Optimiser le code SQL
66 minutes à lire
Objectif
Les efforts d’optimisation doivent d’abord se porter sur le code SQL et la structure des données, avant de considérer des mises à jour matérielles. C’est là où les problèmes se posent en général, et c’est là où l’effet de levier est le plus important. Ce n’est que lorsqu’on a la garantie que le code et le schéma sont optimisés, que la mise à jour matérielle doit être envisagée. Dans ce chapitre, nous allons vous présenter les plans d’exécutions générés par le moteur d’optimisation de SQL Server, qui vont vous permettre de juger de la qualité de votre code SQL. Nous parlerons ensuite de différentes façons d’écrire du code plus performant.
Lire un plan d’exécution
Lorsqu’une requête est reçue par le moteur relationnel, celui-ci vérifie d’abord si son plan d’exécution est présent dans le cache de plans. Si non, il doit créer ce plan. Cette phase est segmentée en quatre étapes. Nous avons schématisé l’exécution d’une requête dans la figure 8.1.
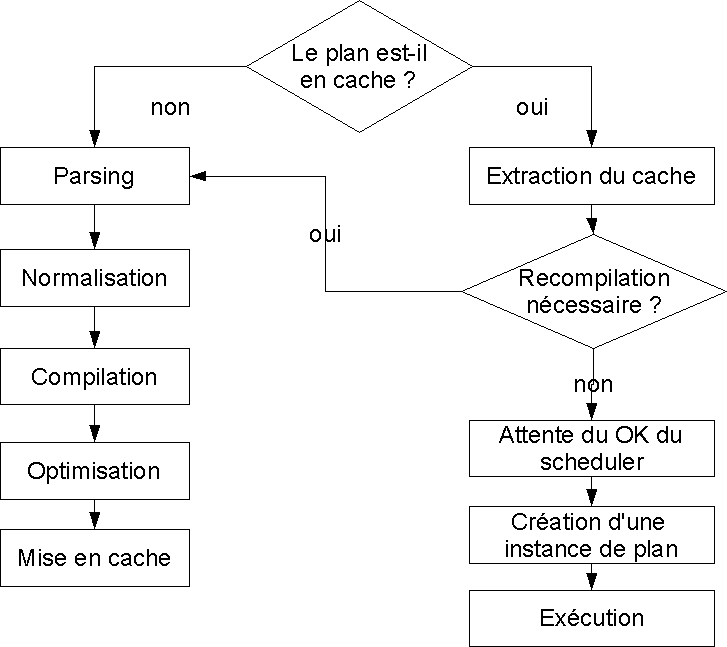
Le moteur de requête parse (évalue) d’abord la requête pour en vérifier la syntaxe, et la réécrit dans une structure qui sera utilisée pour l’optimisation.
La phase de normalisation consiste à vérifier l’existence des objets référencés, et la logique de la requête par rapport à ces objets (SELECT * FROM ProcédureStockée, par exemple, est illogique).
La compilation consiste à bâtir un arbre de séquence (sequence tree) pour décomposer la requête. À cette étape des conversions implicites de types de données sont appliquées si nécessaire, ainsi que le remplacement de l’appel aux vues, par l’appel aux tables sous-jacentes. Un graphe de requête (query graph) est créé, qui est ce qui est envoyé à l’optimiseur.
L’optimisation intervient pour les requêtes DML (SELECT, INSERT, UPDATE et DELETE). L’optimiseur reçoit un graphe de requête, et essaie de trouver la meilleure stratégie d’exécution.
L’optimiseur SQL Server est basé sur le coût (cost-based optimizer), c’est-à-dire qu’il va orienter son choix vers le plan le moins coûteux.
Pour cela, il teste d’abord la possibilité d’utiliser un plan léger (trivial plan).
Dans le cas par exemple d’un simple INSERT …
Le plan ainsi généré est mis en cache, après avoir été potentiellement paramétré en cas d’auto-paramétrage.
Ce plan d’exécution est l’information essentielle dont nous avons besoin pour évaluer la qualité du code de notre requête et ses performances estimées, et pour considérer la création d’index utiles. Nous avons plusieurs moyens de le visualiser. Le plus simple est d’afficher une représentation graphique de ce plan dans SSMS. Deux versions de ce plan y sont disponibles, le plan dit estimé, et le plan dit réel. Le plan estimé est celui qui est produit par l’optimiseur, et qui est affiché avant l’exécution de la requête. Le plan d’exécution réel est le même plan exactement que le plan estimé, puisque ce plan est utilisé sans aucune sorte de modification dynamique en cours d’exécution de la requête. Simplement, le plan réel inclut quelques statistiques d’exécutions effectives, qui peuvent différer des statistiques estimées, principalement sur le nombre de lignes affectées.
La combinaison de touches ==CTRL+L== affiche le plan estimé des instructions de la femêtre de requête active, ou des instructions sélectionnées. ==CTRL+M== prépare l’affichage du plan réel, dans un onglet supplémentaire de la fenêtre de résultat. Vous pouvez aussi les activer par des boutons de la barre d’outils de l’éditeur SQL, indiqués sur la figure 8.2.

Le plan d’exécution est ainsi affiché dans une représentation graphique, qui est l’adaptation synoptique d’un plan généré en format XML.
Ce plan peut être sauvegardé dans un fichier, avec un clic droit sur le plan, et la commande « Save execution plan as … ». L’extension par défaut est .sqlplan.
Lorsque vous ouvrez un fichier portant cette extension avec SSMS, la représentation graphique est générée, ce qui est pratique pour afficher des plans exportés d’une vision XML, ou à partir d’une trace.
Nous trouvons, en figure 8.3, un plan graphique simple.
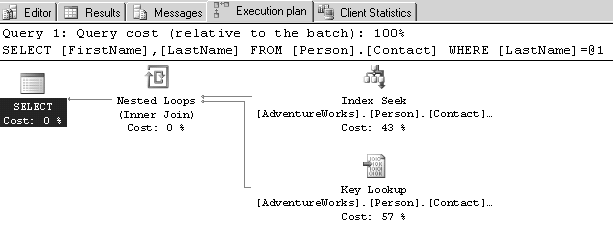
correspondant à la requête :
SELECT FirstName, LastName
FROM Person.Contact
WHERE LastName = 'Abercrombie';
Vous voyez au passage que la requête a été auto-paramétrée par le moteur relationnel, puisque le texte (statement) visible dans le plan d’exécution est :
SELECT [FirstName], [LastName] FROM [Person].[Contact]
WHERE [LastName] = @1;
Nous verrons ce qu’est l’auto-paramétrage dans la section 9.2.
Chaque icône représente un opérateur du plan, c’est-à-dire une opération effectuée sur les données, nous les détaillerons dans la section suivante. Le plan se lit de droite à gauche. La première opération effectuée se trouve en haut et à droite. Chaque opérateur produit une table en mémoire dont le résultat qui est envoyé à l’opérateur suivant, ce qu’expriment les flèches. Le nombre de lignes transportées est représenté visuellement par l’épaisseur des flèches. Sur la figure 8.3, toutes les flèches sont fines, elles ne conduisent donc qu’un petit nombre de lignes. Chaque opérateur, ainsi que l’instruction entière, affichent un coût relatif en pourcent. Lors de l’affichage du plan de plusieurs instruction, le coût par instruction montre une estimation du poids relatif de chacune, ce qui est pratique pour avoir un aperçu des performances comparées de plusieurs syntaxes de requête. La touche F4 permet d’afficher les propriétés du plan ou de chaque opérateur, selon la sélection effectuée à la souris. De même, en laissant le pointeur de la souris posé sur un opérateur ou une flèche, on peut en voir les détails dans une fenêtre de type info-bulle. Nous voyons en figure 8.4 l’affichage des propriétés et de l’info-bulle.
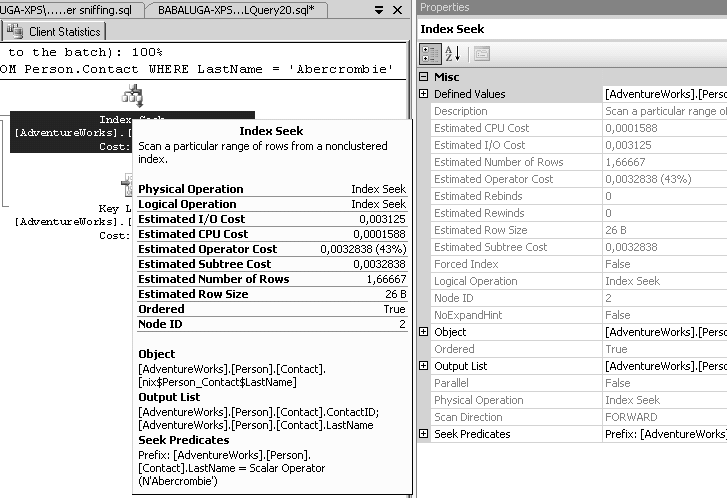
Sont notamment utiles l’estimation du nombre de lignes (produit par l’analyse des statistiques de distribution sur la colonne), et la taille moyenne estimée de la ligne en octets.
La taille multipliée par le nombre nous donne une estimation du volume de données que le moteur de stockage va devoir transmettre d’opérateur à opérateur (nous pouvons voir directement ce calcul dans l’info-bulle des flèches).
Le coût estimé de l’opérateur est une addition des coûts CPU et I/0 estimés.
Vous voyez également sur quel objet est effectuée l’opération (sur la figure 8.4, c’est une recherche dans l’index nix$Person_Contact$LastName), quelles sont les colonnes résultantes qui sont envoyées à l’opérateur suivant (output list), et le prédicat de filtre (le scalaire N'Abercrombie', qui est converti automatiquement en nvarchar pour correspondre au type de données de la colonne LastName).
Le coût du sous-arbre (subtree cost) est simplement la somme du coût de tous les opérateurs précédents plus le courant, indiquant donc ce qu’a déjà coûté le trajet.
Si vous avez désactivé la création ou la mise à jour automatique de statistiques sur votre base de données, vous verrez apparaître un signe d’alerte sur les opérateurs de votre plan qui n’auront pas les statistiques nécessaires à l’estimation d’une cardinalité.
Dans le plan en XML, l’information sera contenue dans un élément <Warnings><ColumnsWithNoStatistics>.
Il peut exister au plus deux versions d’un même plan en cache : une version monoprocesseur et une version parallélisée. SQL Server choisit d’utiliser l’un ou l’autre selon la charge des CPU à l’exécution. Si le plan parallélisé est choisi, tous les opérateurs enrôlés dans l’exécution parallèle seront agrémentés d’une image l’indiquant, comme en figure 8.5.
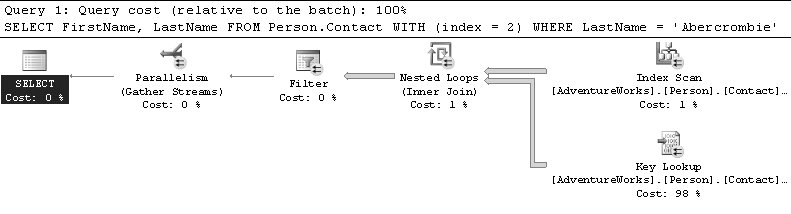
Pour ce plan, nous avons forcé un mauvais plan en ajoutant un indicateur d’index mal à propos. L’exécution en parallèle doit joindre les résultats provenant des différents threads, ce qu’il fait ici dans l’opérateur « Parallelism (Gather Streams) ».
Grâce à cet affichage graphique, vous avez tous les éléments pour comprendre rapidement comment votre requête est exécutée. Afin de l’optimiser, concentrez-vous sur les opérateurs les plus coûteux, et les flèches les plus épaisses. Un des objectifs de l’optimisation est notamment de filtrer le nombre de lignes à traiter au plus tôt dans l’arbre du plan d’exécution, le pire étant représenté par un nombre très important de lignes traitées au début, pour aboutir à un petit nombre en fin de plan. Visuellement, les flèches sont très épaisses à droite, puis très fines à gauche.
Par exemple, que constatons-nous sur la figure 8.5 ? Comme nous avons forcé l’utilisation d’un index inutile pour résoudre le filtre de la clause WHERE, SQL Server est obligé de nous obéir : il parcourt le nœud feuille de l’index (index scan) pour en extraire les ContactID contenus dans la clé de l’index (tous les index contiennent en plus la clé de l’index clustered).
Le résultat, 19 973 lignes sont retournées, pour un total de 125 Ko, comme nous pouvons le voir sur la figure 8.6.
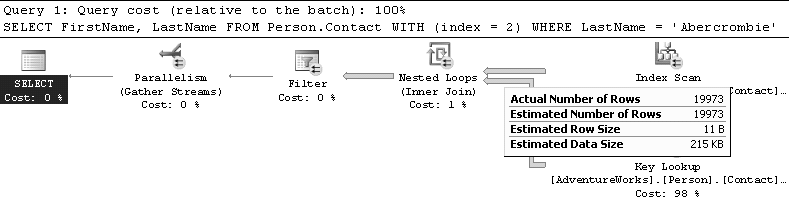
Ces lignes donnant le ContactID, il faut maintenant aller chercher les colonnes FirstName et LastName dans la table.
Pour cela, une recherche à travers l’index clustered doit être faite pour chaque ContactID, ce qui est représenté ici par l’opérateur de boucle imbriquée (nested loop, dont nous parlerons dans la section 8.1.2 sur les algorithmes de jointure).
Pour chaque ligne de la flèche du haut, une recherche est effectuée avec l’opérateur du bas, ici un bookmark lookup de type Key lookup : une recherche (seek) dans l’index clustered.
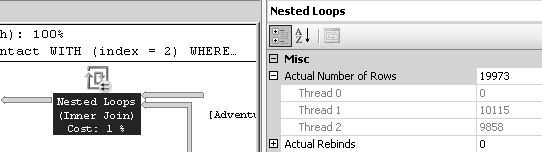
C’est cette opération qui plombe toute la requête, elle vaut pour 98 % de son coût total. En effet, il faut parcourir 19 973 fois l’index clustered. La flèche qui la relie au nested loop le montre (dans le plan estimé, cette flèche est fine, parce que l’estimation qui est faite par SQL Server est de une seule ligne retournée). Dans les propriétés de l’opérateur Nested loop (ou de la flèche qui vient du Key lookup), nous avons l’information du nombre de lignes – donc de seeks de l’index clustered – qui ont été traités par thread, comme nous le voyons sur la figure 8.7.
Lorsque toutes les lignes sont retournées avec la valeur de FirstName et LastName, elles sont envoyées (1,4 Mo passe du nested loop au filter) à un opérateur de filtre, qui, travaillant en mémoire, va éliminer les lignes qui ne correspondent pas au prédicat de recherche LastName = N'Abercrombie'. Il n’en restera que trois lignes, envoyée à la synchronisation des threads parallélisés, puis au client comme jeu de résultats.
Nous verrons un peu plus loin les opérateurs plus en détail.
Récupérer les plan d’exécution
Outre l’affichage graphique intégré à SSMS, vous avez plusieurs moyens de générer des plans d’exécution.
Tout d’abord, un certain nombre de commandes de session permettent l’affichage du plan :
SET SHOWPLAN_XML ON– affiche le plan d’exécution estimé complet en format XML, sans exécuter l’instruction ;SET SHOWPLAN_TEXT ON– affiche le plan d’exécution estimé simplifié en format texte (une ligne de jeu de résultat par opérateur du plan), sans exécuter l’instruction ;SET SHOWPLAN_ALL ON– affiche le plan d’exécution estimé détaillé (avec estimations et alertes) en format texte (une ligne de jeu de résultat par opérateur du plan), sans exécuter l’instruction ;SET STATISTICS XML ON– affiche le plan d’exécution complet réel en format XML, après exécution de l’instruction ;SET STATISTICS PROFILE ON: affiche le plan d’exécution détaillé réel en format texte (une ligne de jeu de résultat par opérateur du plan), après exécution de l’instruction.
Les commandes SET SHOWPLAN... doivent être lancées dans leur propre batch, sans aucune autre instruction.
Vous devez donc les séparer de vos requêtes par un GO dans SSMS.
Les commandes non XML sont considérées par Microsoft comme en voie d’obsolescence, elles seront peut-être supprimées dans une version ultérieure de SQL Server.
Les commandes SET SHOWPLAN… affichent donc le plan estimé, et les commandes SET STATISTICS le plan réel.
Les quelques informations supplémentaires du plan réel sont visibles dans le plan XML dans les éléments <RunTimeInformation> qui y sont ajoutés.
Sur l’affichage graphique du plan, vous les trouvez dans les affichages détaillés lorsque vous glissez votre souris sur un opérateur, ils commencent par « Actual… ».
Vous pouvez aussi récupérer ces plans à partir d’une trace SQL.
Les événements à sélectionner sont dans le groupe d’événements « Performance » :
L’événement Performance statistics se déclenche quand un plan d’exécution est inséré dans le cache de plans, quand il est recompilé, ou quand il est vidé du cache.
La colonne EventSubClass contient l’identifiant du type d’événement, qui peut être un des suivants :
0 – un nouveau batch n’est pas encore dans le cache. La colonne
TextDatacontient le code SQL de la requête ;1 – des instructions dans une procédure stockée ont été compilées ;
2 – des instructions dans un batch de requêtes ad-hoc ont été compilées ;
3 – une requête a été supprimée du cache et les données historiques de performances vont être détruites ;
4 – une procédure stockée a été supprimée du cache et les données historiques de performances vont être détruites ;
5 – un déclencheur a été supprimé du cache et les données historiques de performances vont être détruites.
Les événements 1, 4 et 5 retournent les colonnes DatabaseID et ObjectID, le nom de l’objet (procédure ou déclencheur) peut être retrouvé grâce à la fonction OBJECT_NAME() qui accepte en deuxième paramètre un DB_ID.
Dans les événements 1 et 2, la colonne BinaryData contient le plan d’exécution généré en format binaire, de même les colonnes CPU et Duration donnent les temps de compilation.
La colonne IntegerData donne la taille en kilo-octets, du plan généré.
Les colonnes BigintData1 et BigintData2 donnent respectivement le nombre de fois où ce plan a été recompilé, et la taille mémoire qui a été nécessaire à la compilation, en Ko.
Tous retournent les colonnes SqlHandle et PlanHandle (sauf l’événement 0 qui ne retourne que le SqlHandle) qui donnent des identifiants utiles pour obtenir plus d’informations à partir des vues de gestion dynamique que nous présenterons dans la section suivante.
Les événements Showplan XML, Showplan XML For Query Compile et Showplan XML Statistics Profile affichent des plans en XML dans la colonne TextData :
Showplan XML – retourne le plan d’exécution qui est utilisé par la requête, sans les statistiques d’exécution. Cela correspond au plan estimé. L’événement se déclenche après l’événement SQL ou SP Starting, mais avant
Showplan XML Statistics ProfileShowplan XML For Query Compile – retourne le plan d’exécution tel qu’il est compilé et mis en cache. Cet événement se déclenche durant la phase de compilation, avant exécution (donc avant un événement
Starting), et avant la mise en cache (événementSP:CacheInsert)Showplan XML Statistics Profile – retourne le plan d’exécution utilisé par la requête avec les statistiques d’exécution. Cela correspond au plan réel. L’événement se déclenche juste avant l’événement
SQL CompletedouSP Completed.
Dans les trois cas, BinaryData contient le coût estimé de la requête, et IntegerData le nombre estimé de lignes retournées
ObjectID et ObjectName contiennent l’ID et le nom de l’objet, ObjectType le type d’objet.
Autres événements : Les événements Showplan Text, Showplan Text (Unencoded), Showplan All, Showplan All For Query Compile et Showplan Statistics Profile existent pour compatibilité.
Vous pouvez les utiliser pour voir les plans en format texte.
Les événements produisant des plans en XML sont plus complets et devraient être préférés.
Le Profiler affiche le plan d’exécution graphique, comme SSMS, sur les événements qui retournent ce plan en XML, ou en format binaire, comme nous le voyons sur la figure 8.8.
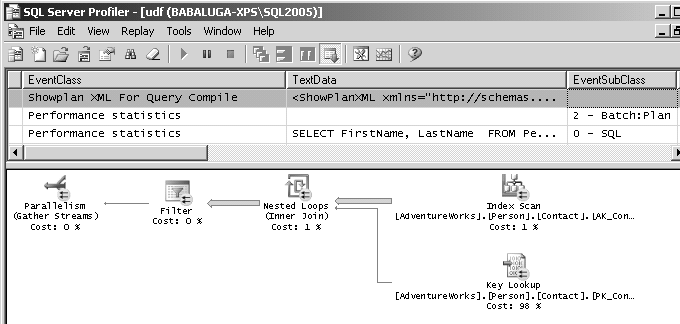
Un dernier mot : la génération en masse de plans d’exécution dans une trace est non seulement inutile et provoque un raz-de-marée d’informations, mais est aussi très pénalisante pour les performances.
Tracez ces événements seulement au besoin, en filtrant votre trace.
Les vues de gestion dynamique
Vous trouvez le code SQL de vos requêtes, ainsi que leur plan d’exécution, dans certaines vues de gestion dynamique, celles qui
lisent le contenu du cache de plans, et celles qui affichent les requêtes exécutées dans le SQL Server, en temps réel. Deux fonctions
permettent de retourner respectivement le code SQL de l’instruction (sys.dm_exec_sql_text) et le plan d’exécution XML (dm_exec_query_plan).
Exemple d’extraction des textes et des plans des tâches en cours :
SELECT er.session_id, er.start_time, er.status, er.command,
st.text, qp.query_plan
FROM sys.dm_exec_requests er
CROSS APPLY sys.dm_exec_sql_text(er.sql_handle) st
CROSS APPLY sys.dm_exec_query_plan(er.plan_handle) qp;
La colonne session_id représente les SPIDs, vous pouvez donc éliminer votre SPID avec un WHERE session_id <> @@SPID, pour éviter de voir cette requête que vous venez de lancer, dans la liste.
Le plan d’exécution (colonne query_plan) étant de type XML, vous pouvez y appliquer du XQuery. Exemple d’extraction du code SQL de l’intérieur du plan :
WITH XMLNAMESPACES (DEFAULT 'http://schemas.microsoft.com/sqlserver/2004/07/showplan')
SELECT
er.session_id, er.start_time, er.status, er.command,
qp.query_plan.value('(/ShowPlanXML/BatchSequence/Batch/Statements/StmtSimple/@StatementText)\[1\]', 'varchar(8000)') as sql_text
FROM sys.dm_exec_requests er
CROSS APPLY sys.dm_exec_query_plan(er.plan_handle) qp
(la ligne de requête XQuery est coupée dans l’exemple).
Ce qui a permis à Bob Beauchemin de créer une intéressante procédure de recherche d’opérateur dans un plan, que nous reproduisons ci-dessous. Vous pouvez la trouver dans cette entrée de blog.
CREATE PROCEDURE LookForPhysicalOps (@op VARCHAR(30))
AS
SELECT sql.text, qs.EXECUTION_COUNT, qs.*, p.*
FROM sys.dm_exec_query_stats AS qs
CROSS APPLY sys.dm_exec_sql_text(sql_handle) sql
CROSS APPLY sys.dm_exec_query_plan(plan_handle) p
WHERE query_plan.exist('
declare default element namespace
"http://schemas.microsoft.com/sqlserver/2004/07/showplan";
/ShowPlanXML/BatchSequence/Batch/Statements//RelOp/@PhysicalOp[. = sql:variable("@op")]') = 1
GO
EXECUTE LookForPhysicalOps 'Clustered Index Scan'
EXECUTE LookForPhysicalOps 'Hash Match'
EXECUTE LookForPhysicalOps 'Table Scan'
8.1.1 Les principaux opérateurs
Les opérateurs de plan sont séparés en deux niveaux. L’opérateur logique représente l’action logique entreprise, au niveau de l’algèbre relationnelle (par exemple, Full Outer Join), ou du concept de recherche.
Dans notre exemple, il s’agit d’une recherche d’index (index seek), un opérateur à la fois logique et physique. Les premiers opérateurs présents sont en général une extraction de données (ou un calcul sur un scalaire).
Vous trouvez la description des opérateurs et leurs icones dans les BOL, sous « Graphical Execution Plan Icons (SQL Server Management Studio) », nous listons ici les plus courants et les plus significatifs.
Bookmark Lookup – recherche de lignes dans une table après parcours ou recherche dans un index nonclustered, à l’aide d’une clé d’index clustered ou d’un RowID. Le bookmark lookup est le plus souvent exprimé dans le plan soit par un opérateur Key Lookup, soit par un opérateur RID Lookup.
Clustered Index Scan – parcours du nœud feuille d’un index clustered, donc de la table elle-même.
Clustered Index Seek – recherche dans un index clustered. Cette recherche n’est jamais suivie d’un bookmark lookup, puisque la table fait partie de l’index clustered.
Split et Collapse – ces opérateurs se rencontrent dans certaines mises à jour (UPDATE) où une contrainte d’unicité doit être vérifiée.
Un UPDATE seul sur une colonne avec contrainte unique pourrait déboucher sur l’insertion de doublons, parce que la mise à jour est exécutée ligne par ligne par le moteur de stockage.
Il faut donc vérifier la totalité des lignes mises à jour en une fois. Cela se fait par la séquence d’opérateurs reproduite en figure 8.9.
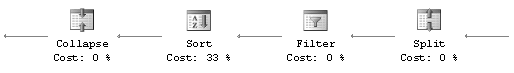
Le split est la séparation d’un UPDATE en un DELETE suivi d’un INSERT.
Des opérateurs de filtre puis de tri organisent les lignes supprimées puis insérées dans l’ordre de la clé unique, afin de vérifier qu’il n’y a pas deux insertions qui portent la même valeur, le collapse réunit ensuite les lignes sur la clé unique (vous trouvez dans le split une propriété GROUP BY qui indique sur quelles colonnes le collapse est effectué)[^26].
Compute Scalar – calcul d’une valeur scalaire à partir d’une expression, et de tout type de source.
Par exemple un COUNT(*) à partir d’un scan d’index est implémenté en tant que Stream Aggregate, puis Compute Scalar.
Un Compute Scalar est visible partout où une colonne doit contenir une valeur calculé, concaténée, etc.
Concatenation – copie des lignes d’un jeu de résultats vers un autre, typiquement utilisé pour un UNION ou UNION ALL.
Dans le cas d’un UNION, si les entrées sont triées, un Merge Join sera souvent préféré, pour permettre un dédoublonnage plus rapide.
Constant Scan – introduit des valeurs constantes comme nouvelles lignes.
Un Compute Scalar est souvent utilisé ensuite pour ajouter des colonnes à cette ligne.
Vous le verrez par exemple lorsque vous voudrez générer un jeu de résultats vide (par exemple pour créer une structure de table vide à l’aide de SELECT INTO).
Des requêtes telles que celles-ci :
SELECT TOP 0 * FROM Person.Address;
SELECT * FROM Person.Address WHERE 1 = 0;
créent un plan très simple, composés d’un seul Constant Scan.
Eager Spool et Lazy Spool – les opérateurs de spool créent une table de travail dans tempdb. Leur différence vient de leur « enthousiasme » à le faire. Le spool enthousiaste (eager) insère toutes les lignes en une seule fois dans la table de travail, alors que le spool paresseux (lazy) le fait une ligne après l’autre : lorsque l’opérateur dépendant du Lazy Spool lui demande une ligne, celui-ci en fait la demande à son opérateur enfant, et stocke la ligne dans le spool.
Filter – filtre un jeu de lignes selon le critère présent dans sa propriété Argument.
Hash Aggregate – calcul d’agrégation utilisé plutôt sur des volumes importants, et uniquement quand la requête utilise un GROUP BY.
Une table de hachage est créée pour permettre un calcul sur tous les sous-ensembles en même temps.
Cette méthode utilise plus de mémoire et verrouille plus que le Stream Aggregate.
Hash Match – test de présence de ligne sur une table de hachage bâtie à partir de l’entrée de l’opérateur enfant (la liste des colonnes faisant partie du hachage est dans le prédicat HASH:() de la propriété Argument).
Les valeurs de hachage sont calculées pour chaque ligne testée et comparées à la table de hachage, pour tester leur présence.
C’est un opérateur physique qui dépend de trois types d’opérateurs logiques :
join – l’opérateur enfant du haut est celui sur lequel la table de hachage est basée, l’opérateur du bas est celui à partir duquel chaque ligne est testée ;
aggregate ou distinct – la table de hachage est créée à partir de l’entrée, les doublons sont supprimés, ou les agrégations calculées, puis la comparaison est faite avec un scan de la même entrée pour conserver les match
union – la table de hachage est calculée à partir de l’opérateur enfant du haut. Les doublons sont éliminés. Les lignes de l’entrée du bas sont testées, et les non-match sont retournés.
Key Lookup – recherche de lignes dans une table clustered, à partir d’une clé d’index clustered présente dans un index nonclustered, après parcours ou recherche de cet index. C’est une de deux formes particulières du bookmark lookup.
Merge Interval – normalise plusieurs intervalles pour en produire un seul, qui sera utilisé dans une recherche d’index.
Nonclustered Index Spool – un index nonclustered est créé sur une table de travail dans tempdb, pour améliorer les performances de recherche dans cette table.
Les opérateurs Remote (Delete, Insert, Query, Scan, Update) indique des opérations sur un serveur distant ou un serveur lié (le plus souvent à travers un serveur lié, linked server, les serveurs distants, remote server, étant obsolètes).
RID Lookup – recherche de lignes dans une table heap, à partir d’un identifiant de ligne (Row ID) présent au niveau feuille d’un index nonclustered, après parcours ou recherche de cet index. C’est une de deux formes particulières du bookmark lookup
Vous verrez souvent des opérateurs de Segment, Sequence et SequenceProject dans les requêtes impliquant des fonctions de fenêtrage (une syntaxe de la norme SQL implémentée en SQL Server depuis la version 2005). Elles servent à calculer le résultat des ces fonctions à l’intérieur du jeu de résultats.
Sort – tri des lignes d’entrée. La propriété ORDER BY indique la ou les colonnes sur lesquelles s’opère le tri.
Spool et Table Spool – Spool sauve le résultat intermédiaire dans une table de travail dans tempdb, Table Spool fait de même à partir des lignes parcourues et sélectionnées dans l’opérateur enfant.
Stream Aggregate – calcul d’agrégation sur un ensemble ou sous-ensemble provenant d’une source triée. Si la source n’est pas déjà triée (elle l’est par exemple si elle provient d’un scan d’index, puisque la clé de l’index est triée), un opérateur Sort devra précéder celui-ci (ou un Hash Aggregate sera utilisé, selon la taille de la table). Vous trouvez dans les proriétés de l’opérateur l’expression de calcul[^27].
Table Scan – scan de table sans index clustered, donc de table heap.
Table-valued Function – une fonction utilisateur retournant une table est appelée. La table retournée est stockée dans tempdb (c’est une variable de type table), elle sera traitée dans tempdb.
UDX – une opération XML, comme un FOR XML ou une requête XQuery.
Les algorithmes de jointure
SQL Server implémente trois algorithmes physiques pour effectuer des jointures. Nous allons les présenter.
La boucle imbriquée (nested loop) est l’algorithme de base, qui est le plus simple et le plus utilisé dans les plans d’exécution. Il consiste à extraire des lignes d’une première table (la table externe), et à rechercher leur correspondance dans une seconde table (la table interne), comme si on cherchait une liste de références dans un premier livre, pour aller chercher chaque référence dans un second.
L’algorithme peut se schématiser ainsi :
- pour chaque ligne de la table externe
- pour chaque ligne de la table externe
- joindre les lignes
- retour des lignes
D’où le nom de boucles imbriquées. Cet algorithme fonctionne très bien pour les petits volumes, mais son coût augmente proportionnellement aux nombres de lignes à traiter.
Les bookmark lookups sont exprimés en boucles imbriquées dans les plan depuis SQL Server 2005.
La fusion (merge join) consiste à prendre deux tables triées selon les mêmes colonnes, et à extraire les correspondances entre la première table et la seconde. Comme elles sont triées, le parcours se fait toujours vers l’avant, chaque correspondance est conservée, et les lignes suivantes sont testées.
C’est donc un algorithme très rapide, mais il implique un tri préalable, et une clause d’équijointure (on ne peut comparer de cette façon que des égalités).
Le tri étant très coûteux, la jointure de fusion est donc utilisée principalement sur les tables ordonnées par un index clustered, ou sur les nœuds feuilles d’index.
Le hachage (hash join) est privilégié sur les jeux de résultats importants, car il permet, après préparation, de réaliser de grosses jointures relativement rapidement.
Il fonctionne en deux phases : il crée premièrement une table de hachage sur les colonnes de la condition de recherche sur la première table. Ensuite, il parcourt la deuxième table, crée un hachage pour chaque condition de recherche et effectue la comparaison avec la table de hachage.
Cet algorithme ne fonctionne qu’avec des clauses d’équijointures.
Il souffre de quelques désavantages : il est « bloquant », car la première étape doit être complètement terminée avant de passer à la seconde (alors que le nested loop et le merge peuvent travailler au fil de l’eau), et il est très consommateur de mémoire.
SQLOS lui réserve une quantité de mémoire estimée pour son travail, mais si cette estimation était trop optimiste, il doit, pendant l’exécution, « baver » sur tempdb (on parle de spilling).
Cela ralentit bien sûr nettement l’opération.
Le hachage est utilisé aussi pour les calculs d’agrégations, et ce débordement peut aussi se produire dans ce cas.
Débordements de hachages
Vous avez un événement de trace qui vous permet de détecter les débordements dans tempdb dûs à des hachages (Hash Aggregate et Hash
Join) : Errors and Warnings : Hash Warning.
Vous pouvez utilisez des indicateurs de requête pour forcer un algorithme de calcul d’agrégation :
option(order group)– force le Stream Aggregateoption(hash group)– force le Hash Aggregate.
Attention à l’option hash group : un Hash Aggregate n’est possible qu’en présence d’un GROUP BY.
Si vous utilisez cet indicateur dans une agrégation scalaire (un calcul d’agrégat sans regroupements, donc sans clause GROUP BY), une erreur vous sera renvoyée à la compilation :
« Query processor could not produce a query plan because of the hints defined in this query… ».[^28]
gestion avancée des plans d’exécution
Vous pouvez modifier le plan d’exécution généré par l’optimiseur de deux façons, soit en ajoutant à la requête des indicateurs spécifiques forçant certaines stratégies logiques ou physiques de résolution de la requête, soit en y appliquant un plan d’exécution « fait main » complet, à l’aide des guides de plan (plan guides).
Nous allons passer les deux solutions en revue.
Mais avant cela, il nous faut répéter encore que ces fonctionnalités ne sont à considérer qu’en dernier ressort, et lorsque vous savez ce que vous faites. Soyez notamment conscient des répercutions lors de changement de structure ou de distribution des valeurs dans les tables.
Par exemple, un guide de plan qui force l’utilisation d’un index qui a disparu, génère une erreur.
les indicateurs de requête et de table
Vous avez à disposition des indicateurs (hints) permettant d’indiquer à l’optimiseur une stratégie préférée, voire de le forcer à utiliser une méthode, un index, et jusqu’à un plan d’exécution prédéfini.
Certains de ces indicateurs sont intéressants, mais ils ne devraient être utilisés qu’en cas de réel besoin.
Le moteur d’optimisation de SQL Server est très performant, et le forcer à se comporter d’une certaine manière est en général contre-indiqué.
Cette mise en garde faite, nous allons présenter ici ces indicateurs, et tâcher d’expliquer quand ils peuvent être utilisés, et quand ils ne devraient pas l’être.
On utilise un indicateur à même la requête, soit à la fin de celle-ci avec la clause OPTION() pour les indicateurs de requête (query hints), soit après une table avec la clause WITH() pour les indicateurs de tables (table hints).
Voici un exemple d’utilisation d’un indicateur de requête forçant un certain algorithme de jointure :
SELECT *
FROM Sales.Customer c
JOIN Sales.CustomerAddress ca
ON c.CustomerID = ca.CustomerID
WHERE TerritoryID = 5
OPTION (MERGE JOIN);
Indicateurs de requête
Les indicateurs de requête disponibles sont les suivants :
{ HASH | ORDER } GROUP
{ CONCAT | HASH | MERGE } UNION
{ LOOP | MERGE | HASH } JOIN
Ces trois indicateurs permettent de forcer les algorithmes d’agrégation (voir section 8.1.1 plus haut), d’UNION et de jointure. Évitez de forcer ce choix, à de rares exceptions près, l’optimiseur sait ce qu’il fait.
FAST nombre_de_lignes
Précise que la requête doit être optimisée pour renvoyer d’abord un nombre spécifique de lignes au client, avant de poursuivre. Cette clause peut être utile pour un affichage rapide sur une première page de pagination.
Elle permet, comme la clause TOP, de profiter de la fonctionnalité d’objectif de lignes (row goal), qui peut modifier le plan d’exécution en conséquence.
C’est une bonne chose pour le retour du nombre de lignes indiqué, mais potentiellement au détriment des performances de la requête entière.
Il s’agit donc d’une option à double tranchant, qui peut empirer les choses[^29]. Il est préférable d’utiliser la clause TOP, qui garantit le retour du nombre de lignes indiqué.
FORCE ORDER
Spécifie que l’ordre des tables dans la déclaration de jointure doit être conservé.
Cette option est rarement utile, mais si vous avez un soupçon de mauvaise génération de plan, vous pouvez essayer différents ordres d’apparition des tables dans votre clause FROM, avec cette option, pour voir quelle est la combinaison gagnante.
Une fois de plus, un changement structurel de tables, et la modification de la stratégie d’indexation, peut changer le plan optimal, qui ne pourra plus alors être automatiquement choisi par l’optimiseur.
MAXDOP nombre_de_processeurs
Vous permet d’indiquer un nombre de processeurs maximum impliqué dans une parallélisation de la requête.
Rappelons que la parallélisation maximum peut être définie au niveau du serveur par l’option « maximum degree of parallelism ».
Cet indicateur vous permet d’attribuer une autre valeur à une requête spécifique, ce qui peut se révéler utile soit pour désactiver le parallélisme sur une requête coûteuse (MAXDOP 1), soit pour l’activer sur une requête alors qu’il est désactivé au niveau du serveur. Rappelons également que cette option ne signifie pas que SQL Server va nécessairement paralléliser la requête.
On lui en donne la possibilité, et il fait son choix selon le coût de la requête (selon l’option de serveur « cost threshold for parallelism ») et la charge actuelle des processeurs de la machine.
OPTIMIZE FOR ( @variable_name = literal_constant [ , …n ] )
Indique à l’optimiseur de générer un plan optimisé pour une valeur de paramètre donnée, ce qui est très utile pour déjouer les pièges du parameter sniffing (voir section 9.1.1).
Il vous suffit d’indiquer une valeur distribuée de façon représentative dans votre colonne, pour éviter la compilation avec des plans extrêmes.
SQL Server 2008 ajoute plus de souplesse à cet indicateur :
OPTIMIZE FOR UNKNOWN – tous les paramètres sont considérés avec une valeur de distribution moyenne de la colonne
OPTIMIZE FOR ( @variable_name = UNKNOWN) – une valeur de distribution moyenne est considérée pour ce paramètre.
Cela permet d’éviter dans tous les cas les valeurs extrêmes.
En général, pour les colonnes qui ont une distribution très hétérogène (quelques valeurs très sélectives, d’autres avec beaucoup de doublons), une stratégie de scan sera choisie.
Il est inutile de spécifier cet indicateur pour des colonnes avec une contrainte ou un index unique. Dans ce cas le plan n’a pas de risque d’être mal estimé.
RECOMPILE
Force la recompilation systématique de l’instruction. Utile à l’intérieur d’un objet de code. Nous le verrons plus en détail dans la section 9.1.1.
PARAMETERIZATION { SIMPLE | FORCED }
Force un auto-paramétrage. Nous verrons cet indicateur plus en détail dans la section 9.2.
KEEP PLAN, KEEPFIXED PLAN
permet de diminuer le nombre de recompilations produites sur une instruction dans un objet de code.
Au fil des versions, SQL Server provoque de moins en moins de recompilation en cachant de mieux en mieux les instructions individuellement.
KEEP PLAN diminue le nombre de recompilations dûes à des changements de cardinalité (utile pour une table temporaire, qui va provoquer une recompilation après une insertion première de six lignes), KEEPFIXED PLAN empêche une recompilation dûe à des changements de statistiques de distribution.
Nous le verrons plus en détail dans la section 8.3.1.
EXPAND VIEWS
Indique que les index d’une vue indexée ne doivent pas être utilisés pour satisfaire la requête, mais que le plan doit se calculer sur les tables sous-jacentes.
L’indicateur de table WITH(NOEXPAND) provoque l’effet inverse : seuls les index de la vue sont considérés.
MAXRECURSION nombre_de_récursions
Limite le nombre d’appels récursifs dans une expression de table (common table expression, CTE) récursive.
USE PLAN N’xml_plan’
Vous permet de « coller » un plan d’exécution en format XML.
Cet indicateur ne peut être utilisé que dans un SELECT.
C’est l’indicateur le plus dangereux, car il fixe tout le plan d’exécution dans le marbre.
Il suffit qu’un élément de la structure de table qui y est référencé soit supprimé, pour provoquer une erreur d’exécution. De même, une fonctionnalité de plan modifiée dans une version ultérieur invalide aussi le plan. N’utilisez cette fonctionnalité qu’en dernier ressort, quand par exemple vous connaissez un meilleur plan, généré par une version antérieure de SQL Server, et que la mise à jour a dégradé les performances.
Vous pouvez récupérer le plan à l’aide de SET SHOWPLAN_XML, et le passer à la requête.
Envoyez ce plan en UNICODE, avec le N devant le littéral, pour éviter des conversions de caractère indésirables à l’enregistrement du plan. Le plan doit pouvoir être validé par le schéma Showplanxml.xsd, disponible dans le répertoire d’installation de SQL Server, ou sur le site de Microsoft.
Une option de session : SET FORCEPLAN { ON | OFF }, force également les plans d’exécution de deux façons : les instructions exécutées dans la session respecteront l’ordre d’apparition des tables dans la clause FROM, et l’opérateur de jointure en boucle imbriquée (nested loop) sera partout utilisé, à moins qu’un indicateur force un autre algorithme.
Autant dire que cette option est à laisser à OFF.
Indicateurs de table
les indicateurs de table s’ajoutent après la déclaration de table, dans une clause FROM, comme ceci :
SELECT FirstName, LastName
FROM Person.Contact WITH (READUNCOMMITTED);
Nous en listons ici les principaux, la plupart touchent les verrouillage, nous ne les abordons que succintement, entrant plus en détail sur le sujet dans le chapitre 7.
FORCESEEK – force une stratégie de seek d’index plutôt qu’un scan
NOEXPAND – force l’utilisation des index sur une vue indexée
INDEX ( index_val [ ,…n ] ) – force l’utilisation d’un index (même s’il n’a rien à voir avec le critère de filtre de la clause WHERE
HOLDLOCK – force le niveau d’isolation SERIALIZABLE pour la table
NOLOCK – force le niveau d’isolation READ UNCOMMITTED pour la table
NOWAIT – désactive l’attente de verrous. Si la table est verrouillée à l’exécution de la requête, SQL Server renvoie une erreur immédiatement
PAGLOCK – force le choix d’une granularité de verrous par pages, au lieu d’une granularité par ligne ou par table
READCOMMITTED – force le niveau d’isolation
READ COMMITTEDpour la table (niveau d’isolation par défaut de SQL Server), utilise le row versioning si la base est en isolationREAD_COMMITTED_SNAPSHOTREADCOMMITTEDLOCK – force le niveau d’isolation
READ COMMITTEDpour la table, sans utiliser le row versioning même si la base est en modeREAD_COMMITTED_SNAPSHOTREADPAST – force la lecture d’une table sans attendre la libération des verrous incompatibles. Cela peut donc entraîner une lecture incomplète, mais rapide (on n’obtient donc que l’argent du beurre, mais pas forcément le beurre). Par exemple, le code suivant ne va lire que quatre lignes sur cinq (les nombres 1, 2, 4, 5) :
CREATE TABLE dbo.ReadPast (nombre int not null)
INSERT INTO dbo.ReadPast (nombre)
VALUES (1), (2), (3), (4), (5);
BEGIN TRAN
UPDATE dbo.ReadPast SET nombre = -nombre
WHERE nombre = 3
-- dans une autre session
SELECT *
FROM dbo.ReadPast WITH (READPAST)
READUNCOMMITTED – force le niveau d’isolation
READ UNCOMMITTEDpour la table, strictement équivalent àNOLOCKREPEATABLEREAD – force le niveau d’isolation
REPEATABLE READpour la table. Ce n’est donc intéressant que dans une transaction explicite ;ROWLOCK – force le choix d’une granularité de verrous par ligne (granularité par défaut de SQL Server), empêche donc normalement l’escalade. Sans garantie. Par exemple, en niveau d’isolation
SERIALIZABLE, des verrous plus larges doivent de toute façon être posés ;SERIALIZABLE – force le niveau d’isolation
SERIALIZABLEpour la table, strictement équivalent àHOLDLOCK;TABLOCK – force le choix d’une granularité de verrou par table. Pose un verrou partagé (S) ;
TABLOCKX – force le choix d’une granularité de verrou par table. Pose un verrou exclusif (X) ;
UPDLOCK – force un verrouillage de mise à jour (U) ;
XLOCK – force un verrouillage exclusif (X).
Les guides de plan
Les guides de plan permettent de forcer des indicateurs de requêtes sur une instruction sans la modifier directement.
Ils sont utiles pour appliquer des indicateurs à des requêtes sur lesquelles vous n’avez pas la main.
Vous créez simplement un guide de plan à l’aide de la procédure stockée système sp_create_plan_guide, et vous modifiez, désactivez ou activez ce guide par la procédure sp_control_plan_guide.
Vous pouvez créer trois types de guides :
Un guide pour une instruction dans un OBJET de code : procédure stockée, fonction utilisateur, déclencheur ;
un guide SQL, pour des requêtes ad-hoc ;
un guide de type TEMPLATE, pour modifier le comportement d’autoparamétrage d’une classe de requêtes. Ce type ne permet que de modifier l’indicateur
PARAMETERIZATIONde la requête.
Vous spécifiez le type dans le paramètre @type à la création du guide.
Voici un exemple d’utilisation de guide de plan :
CREATE PROCEDURE dbo.GetContactsForPlanGuide
@LastName nvarchar(50) = NULL
AS BEGIN
SET NOCOUNT ON
SELECT FirstName, LastName
FROM Person.Contact
WHERE LastName LIKE @LastName;
END
GO
EXEC dbo.GetContactsForPlanGuide 'Abercrombie'
EXEC dbo.GetContactsForPlanGuide '%'
-- pas bon
GO
EXEC sys.sp_create_plan_guide
@name = N'Guide$GetContactsForPlanGuide$OptimizeForAll',
@stmt = N'SELECT FirstName, LastName
FROM Person.Contact
WHERE LastName LIKE @LastName',
@type = N'OBJECT',
@module_or_batch = N'dbo.GetContactsForPlanGuide',
@params = NULL,
@hints = N'OPTION (OPTIMIZE FOR (@LastName = ''%''))'
EXEC dbo.GetContactsForPlanGuide '%'
-- mieux !
GO
-- suppression
SELECT * FROM sys.plan_guides
EXEC sys.sp_control_plan_guide
@Operation = N'DROP',
@Name = N'Guide$GetContactsForPlanGuide$OptimizeForAll'
Dans cet exemple, nous avons créé une procédure stockée qui est exécutée la première fois avec un paramètre provoquant une compilation de plan d’exécution utilisant un seek d’index, par parameter sniffing (voir section 9.1.1).
Le deuxième appel utilisera un plan d’exécution très défavorable.
Nous créons ensuite un guide de plan qui utilise l’indicateur OPTIMIZE FOR pour forcer une compilation prenant en compte une valeur de paramètre générique (un scénario du pire, qui sera désagréable pour les valeurs de paramètre qui profiteraient d’un index, à cause de leur grande sélectivité, mais qui limitera les dégâts en cas d’envoi de paramètre trop peu sélectif).
Pour supprimer le guide de plan, nous utilisons le paramètre @Operation = N'DROP' en appel de sp_control_plan_guide.
Nous pourrions aussi désactiver le plan par la valeur 'DISABLE'.
En SQL Server 2008, les événements de trace Performance : Plan Guide Successful Event et Performance : Plan Guide Unsuccessful Event vous indiquent les plans d’exécutions créés à l’aide d’un guide, ou si la création du plan a échoué.
De même, dans SSMS, vous trouvez la liste des guides de plan dans l’explorateur d’objets, sous le nœud Programmability.
La vue système sys.plan_guides liste les guides de plan enregistrés dans la base courante.
optimiser son code sql
Un SGBDR est un serveur dont le travail est d’assurer un stockage des données optimal et cohérent. Il est maître de ses données. SQL est un langage de requête (le nom est bien choisi) dont l’expression est déclarative : via une requête SQL, le programmeur décrit le résultat désiré.
Par exemple, une requête comme celle-ci :
SELECT FirstName, LastName
FROM Person.Contact
WHERE Title = 'Mr.'
ORDER BY LastName, FirstName;
est purement « descriptive » : on y demande une liste des prénoms et noms de contacts, lorsque leur titre est « Mr. », triés par nom et prénom.
À aucun moment, on indique au serveur comment produire cette liste.
Tout à fait comme lorsque vous allez dans une librairie commander un livre, vous demandez simplement à votre libraire de passer commande d’un ouvrage, vous ne lui dites pas : « pourriez-vous faire une recherche dans votre catalogue de livres distribués, pour noter le numéro ISBN du titre que je souhaite obtenir, pour le copier-coller dans votre programme de commande, et y inscrire mon nom. Ensuite, merci d’imprimer un bon de commande pour le faire parvenir par voie postale au distributeur de ces éditions. »
Votre libraire est bien plus qualifié que vous pour effectuer cette tâche, et d’ailleurs, si vous le forciez à utiliser votre méthode, la commande prendrait peut-être plus de temps, ou même ne serait-elle jamais faite correctement.
SQL Server fonctionne de la même façon.
Si la syntaxe du langage est déclarative, son exécution sera finalement procédurale : le moteur d’optimisation, qui fait partie du moteur relationnel, est un bijou d’algorithmique. La stratégie de plan d’exécution se base sur les connaissances dont dispose le moteur d’optimisation sur la structure et le contenu des tables et des vues. Le travail du programmeur SQL est d’écrire la requête la plus descriptive possible, pour donner l’information précise de ce que la requête doit obtenir.
Durant la phase de compilation, le moteur relationnel a une grande capacité à normaliser les syntaxes équivalentes pour produire l’arbre d’exécution. Par exemple, ces requêtes produisent (presque) le même plan (sur SQL Server 2005) :
SELECT c.FirstName, c.LastName
FROM Person.Contact c
CROSS JOIN HumanResources.Employee e
WHERE c.ContactId = e.ContactId;
SELECT c.FirstName, c.LastName
FROM Person.Contact c
JOIN HumanResources.Employee e ON c.ContactId = e.ContactId;
SELECT c.FirstName, c.LastName
FROM Person.Contact c
WHERE EXISTS (SELECT *
FROM HumanResources.Employee e WHERE c.ContactId = e.ContactId);
SELECT c.FirstName, c.LastName
FROM Person.Contact c
WHERE c.ContactId IN (
SELECT e.ContactId
FROM HumanResources.Employee e);
Les deux premiers plan sont identiques, les deux suivants aussi, qui incluent un tri (distinct sort).
Le nombre de reads est identique, et considérant la faible volumétrie (290 lignes retournées), les performances sont, dans les faits, les mêmes, même si les deux derniers plans sont plus coûteux.
Il n’est donc souvent pas utile de choisir une syntaxe légèrement différente d’une autre pour améliorer les performances.
Testez les plans d’exécution, et choisissez la syntaxe la plus intuitive et la plus lisible.
De même, l’ordre d’apparition des colonnes dans le SELECT, des tables dans la clause FROM et des expressions dans les clauses WHERE et HAVING, n’a pas d’importance.
La requête sera de toute manière décomposée et récrite durant la phase de compilation.
Sur certains SGBDR, l’ordre des tables dans la jointure influe sur les performances. Ce n’est pas le cas en SQL Server.
En revanche, l’ordre des colonnes dans les clauses GROUP BY et ORDER BY peut modifier les performances, en influant sur les tris, opérations coûteuses.
Écriture ensembliste
Nous l’avons dit, le langage SQL est déclaratif, il est aussi ensembliste : toutes les instructions définissent et travaillent sur des ensembles de données, avec parfois des entorses à l’algèbre relationnelle (la clause ORDER BY par exemple est une hérésie pour le modèle relationnel, où les tuples d’une relation n’ont aucun ordre précis.
SQL permet de générer un jeu de résultat ordré, ce qui viole la théorie relationnelle, mais est très utile).
Il est donc important d’éviter le plus possible des syntaxes non déclaratives et non ensemblistes, le plus triste exemple étant le curseur.
Les boucles WHILE entrent dans ce cas de figure.
Nous avons également dit que, bien que le langage est ensembliste, l’exécution est procédurale : le moteur de stockage doit finalement parcourir les lignes ou les clés d’un index une à une.
Ce simple exemple suffit à la démontrer :
DECLARE @i int;
SET @i = 0;
SELECT @i = @i + 1 FROM Person.Contact;
SELECT @i;
après exécution, @i vaut 19973, ce qui est la cardinalité de la table Person.Contact.
Pour des considérations de performances, cela signifie une chose : même si la requête est écrite en pur SQL, elle peut être plus ou moins efficace selon la stratégie décidée par l’optimiseur.
Certaines construction SQL permettent des stratégies optimales, d’autres forcent le plan à utiliser des opérations proches d’un fonctionnement de curseur.
C’est notamment le cas de syntaxes introduites dans SQL Server 2005, comme la clause PIVOT et les fonctions de fenêtrage.
Leur utilité est donc à balancer avec leur coût, et elles sont à bannir autant que possible, surtout lorsqu’une syntaxe plus traditionnelle existe.
Prenons un exemple. Nous voulons obtenir une liste des contacts avec, pour chaque ligne, le nombre total de personnes portant le même nom de famille. Nous pouvons utiliser une sous-requête ou une fonction de fenêtrage :
-- SELECT avec sous-requête
SELECT
t.FirstName,
t.LastName,
(SELECT COUNT(*)
FROM Person.Contact
WHERE LastName = t.LastName) cnt
FROM Person.Contact t
GO
-- SELECT avec fonction de fenêtrage
SELECT
t.FirstName,
t.LastName,
COUNT(*) OVER (PARTITION BY LastName) as cnt
FROM Person.Contact t;
Nous voyons le résultat de la trace sur la figure 8.10.
La requête utilisant la sous-requête a nécessité environ 1 200 reads, alors que celle utilisant la fonction de fenêtrage a lu 47 000 pages, et en a écrit 12. La raison de ces lectures et écriture est la création d’une table de travail (opérateur table spool).
À l’heure actuelle, dans SQL Server 2005, la première requête est donc bien plus performante.

Ce choix entre une syntaxe ou une autre n’a pas de valeur absolue, et c’est pour cette raison que nous disons « à l’heure actuelle ». Comme l’optimiseur SQL évolue, il est possible que le plan d’exécution de la fonction de partitionnement s’améliore dans le futur. Il paraît toutefois peu probable qu’il finisse par dépasser en performances la syntaxe utilisant la sous-requête. La règle de base qu’on peut en déduire est celle-ci : lorsque c’est possible, choisissez la syntaxe la plus « intuitive » et la plus « traditionnelle ». La clarté aide l’optimiseur, et les syntaxes plus anciennes, bien connues, ont plus de chance de bénéficier d’optimisations solides.
Comparaisons et filtres
Dans la clause WHERE d’une requête, comme dans la clause ON d’une jointure, peuvent êtres exprimées des expressions de filtre.
Ces expressions retournent un résultat en logique ternaire : VRAI, FAUX ou INCONNU.
Elles sont composées d’un opérateur et de deux opérandes (à gauche et à droite de l’opérateur).
La plupart du temps, une des opérandes au moins est une colonne de table.
L’autre opérande, la valeur recherchée. Par exemple :
SELECT LastName, FirstName
FROM Person.Contact
WHERE LastName LIKE 'Al%';
Si la colonne recherchée est indexée, l’optimiseur va peut-être choisir d’utiliser l’index dans le plan d’exécution, selon la sélectivité de celui-ci. Si les estimations de l’optimiseur lui montrent qu’un scan de la table ou d’un index sera moins coûteux en lectures qu’une recherche dans les clés de l’index, le scan sera choisi. Cela dépend du nombre de lignes retournées par la requête. Quoiqu’il en soit, en l’absence d’un index utile, SQL Server sera obligé d’exécuter un scan. Considérez donc la création d’index sur les colonnes présentes dans vos expressions de filtre, et testez après création si l’index est utilisé par la requête.
Cette règle est bien entendu valable pour les expressions de jointure :
SELECT c.LastName, c.FirstName, a.AddressLine1, a.PostalCode, a.City
FROM Person.Contact c
JOIN HumanResources.Employee e ON c.ContactId = e.ContactId
JOIN HumanResources.EmployeeAddress ea ON e.EmployeeId = ea.EmployeeId
JOIN Person.Address a ON ea.AddressId = a.AddressId;
Dans cet exemple, les expressions de la clause ON des jointures effectuent des recherches sur les colonnes tout comme la clause WHERE.
Elles bénéficient donc de la présence d’index.
Les clés des tables mères sont déjà indexées : en règle générale, une jointure est effectuée entre une ou plusieurs colonnes liées par une contrainte de clé étrangère (bien que rien dans le langage SQL ne force la jointure à s’appuyer sur un telle définition de modèle).
La clé étrangère ne peut s’appuyer que sur une clé primaire ou unique de la table mère. Ces clés créent nécessairement des index. Par exemple, La colonne ContactId de la table Person.Contact est clé primaire clustered.
En revanche, la création de clé étrangère en SQL Server ne force en rien la création d’un index sur la clé déportée dans la table fille.
C’est à vous de le faire, et c’est pratiquement une étape nécessaire pour assurer la bonne performance des requêtes de jointure.
Pour qu’une expression de filtre utilise l’index, il est impératif que la colonne soit présente comme opérande, sans aucune modification.
C’est ce qu’on appelle un SARG (Search ARGument). Un seek d’index ne peut être évalué comme possibilité que sur une opérande de type SARG, c’est-à-dire qui correspond exactement à ce qui est stocké dans la clé de l’index. Toute modification de colonne dans l’expression, comme par exemple une concaténation, un passage dans une fonction, ou un changement de collation à la volée, empêchera toute utilisation d’index, et forcera par conséquent le scan.
C’est donc à éviter.
Exemples de choses à ne pas faire :
SELECT FirstName, LastName
FROM Person.Contact
WHERE LastName COLLATE Latin1_General_CI_AI = 'Jimenez';
SELECT FirstName, LastName
FROM Person.Contact
WHERE LEFT(LastName, 2) = 'AG';
SELECT FirstName, LastName
FROM Person.Contact
WHERE LastName + FirstName = 'AlamedaLili';
à la place, écrivez vos filtres comme ceci :
SELECT FirstName, LastName
FROM Person.Contact
WHERE LastName LIKE 'Jim[eé]nez';
SELECT FirstName, LastName
FROM Person.Contact
WHERE LastName LIKE 'AG%';
SELECT FirstName, LastName
FROM Person.Contact
WHERE LastName = 'Alameda' AND FirstName = 'Lili';
L’opérateur LIKE permet l’utilisation de l’index, à condition que le début de la chaîne soit fixe.
Il correspond ainsi au début de la clé de l’index, et est donc SARGable, comme on peut chercher efficacement dans un annuaire en ne connaissant que les quelques premières lettres d’un nom.
Cette règle est valable aussi pour les opérations arithmétiques. SQL Server n’est pas capable de modifier une expression contenant des opérations sur des constantes pour la simplifier, une opération connue en compilation sous le nom de constant folding.
Prenons un exemple :
SELECT *
FROM Person.Contact
WHERE ContactId + 3 = 34;
SELECT *
FROM Person.Contact
WHERE ContactId = 37;
Il n’est pas très difficile pour un compilateur de transformer automatiquement la première clause en la seconde.
Pourtant, SQL Server ne le fait pas, comme nous le voyons dans les plans d’exécution en figure 8.11.
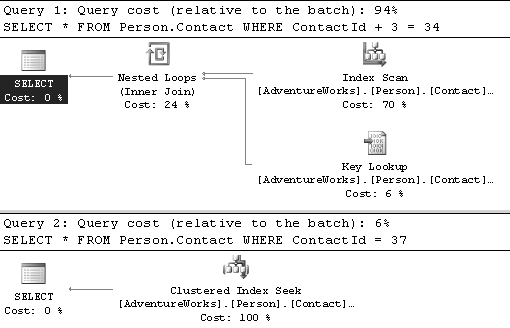
La règle à suivre est donc celle-ci : une des deux opérandes doit être la colonne, seulement la colonne, et rien que la colonne.
Dans la liste des opérateurs disponibles, l’égalité (=) est le plus utilisé.
C’est celui qui offre le plus de possibilité d’optimisation par un index.
L’opérateur de différence (<>) est souvent le moins efficace, non pas parce qu’il empêche en tant que tel l’utilisation d’un index, mais parce qu’il provoque souvent la sélection d’un nombre important de lignes.
En réalité, les opérateurs qui provoquent une recherche de plage, sont à manier avec précaution, car ils peuvent entraîner le retour d’un grand nombre de lignes.
Ces opérateurs sont <, >, <=, >=, BETWEEN et <>.
Grandeur et misère des fonctions utilisateur
Les fonctions utilisateur (User defined functions, UDF) sont des objets de code, au même titre que les procédures stockées et les déclencheurs.
Leur travail est de retourner une valeur scalaire ou une table au code T-SQL appelant.
Elles peuvent sembler très pratique au premier abord, car elle permettent de réaliser le rêve de tout programmeur : la diminution du code redondant par modularisation. Avons-nous besoin de faire une recherche répétitive sur une table, pourquoi ne pas encapsuler cette recherche dans une fonction ?
Parce que, ce qui paraît à première vue une bonne idée pour le programmeur, se révèle une très mauvaise idée pour un SGBDR.
Nous pourrions songer à modulariser notre code de la façon suivante : au lieu d’utiliser des sous-requêtes ou des jointures, nous serions tentés d’aller chercher les valeurs ou les calculs qui nous intéressent à l’aide d’une fonction.
En reprenant notre exemple du compte de noms de famille, essayons de modulariser le code, pour réutiliser ce calcul dans toutes circonstances.
Nous créons alors la fonction suivante :
CREATE FUNCTION Person.GetCountContacts (@LastName nvarchar(50))
RETURNS int
AS BEGIN
RETURN (SELECT COUNT(*)
FROM Person.contact
WHERE LastName LIKE @LastName)
END;
Nous profitons ainsi d’une fonction qui retourne le compte des contacts pour toute la table (paramètre ‘%’), par début de nom (paramètre 'A%' par exemple, ou par nom (paramètre 'Ackerman' par exemple) :
SELECT Person.GetCountContacts('%');
SELECT Person.GetCountContacts('A%');
SELECT Person.GetCountContacts('Ackerman');
Pratique, non ?
Peut-être dans ce contexte-là, mais gardons-nous d’inclure cette fonction dans la clause SELECT d’une requête.
Observons les différences de performances entre trois façons d’obtenir les mêmes résultats :
-- SELECT avec utilisation de la fonction
SELECT
t.FirstName,
t.LastName,
Person.GetCountContacts(t.LastName) as cnt
FROM Person.Contact t;
-- SELECT avec sous-requête
SELECT
t.FirstName,
t.LastName,
(SELECT COUNT(*)
FROM Person.Contact
WHERE LastName = t.LastName) cnt
FROM Person.Contact t;
Nous avons tracé ces requêtes. Voyons le résultat sur la figure 8.12.

La requête utilisant la fonction dure huit secondes et lit près de 46 000 pages, alors que la solution avec sous-requête, une seconde (125 millisecondes de temps CPU) pour 1200 pages lues. La différence est sans appel.
Pourquoi ? Parce qu’avec la fonction, nous forçons SQL Server à utiliser la stratégie de requête que nous avons décidée.
Pour chaque ligne de la table Person.Contact impliquée dans la requête, SQL Server doit entrer dans la fonction et exécuter la requête qui s’y trouve à nouveau.
Puisque nous avons séparé le code en deux objets, l’optimiseur n’a aucun moyen de lier les deux requêtes pour comprendre ce qu’on veut obtenir.
Ainsi la nature déclarative du langage SQL est violée.
En revanche, en incluant avec une sous-requête les deux opérations dans la même requête, l’optimiseur a tout en main pour la décortiquer, la comprendre, et l’optimiser. Regardons le plan d’exécution (un peu nettoyé pour faciliter sa lecture) de l’ordre utilisant la sous-requête :
|--Compute Scalar
|--Hash Match(Right Outer Join ...)
|--Compute Scalar ...
| |--Stream Aggregate( ...
| |--Index Scan(OBJECT:(...
[nix$Person_Contact$LastName]), ...)
|--Clustered Index Scan(OBJECT:(...
[PK_Contact_ContactID] AS [t]))
La conclusion est simple : méfiez-vous des fonctions.
Compter les lignes d’une table
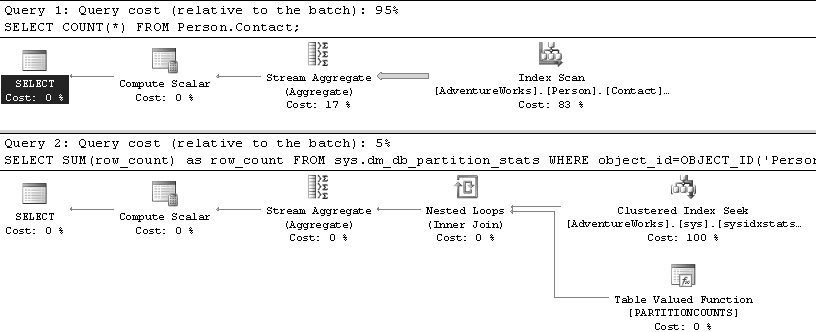
Pour compter le nombre total de lignes d’une table, vous n’êtes pas obligé de faire un COUNT, vous pouvez vous baser sur les informations de métadonnées, qui sont, autant que nous avons pu en faire l’expérience, toujours à jour.
Évidemment, cette astuce n’est valable que si vous voulez la cardinalité de toute la table, non filtrée. Démonstration :
SELECT COUNT(*)
FROM Person.Contact;
GO
SELECT SUM(row_count) as row_count
FROM sys.dm_db_partition_stats
WHERE object_id = OBJECT_ID('Person.Contact')
AND ( index_id = 0 or index_id = 1 );
GO
Résultat en reads :
Table 'Contact'. Scan count 1, logical reads 46, ...
Table 'sysidxstats'. Scan count 2, logical reads 4, ...
-- sys.dm_db_partition_stats
Les tables temporaires
Les tables temporaires, bien qu’elles soient déclarées dans tempdb, restent en mémoire, dans le buffer, jusqu’à ce qu’elles atteignent une taille qui nécessite leur écriture sur disque.
Vaut-il mieux utiliser les variables de type table ?
SQL Server 2000 a introduit la variable de type table, c’est-à-dire la possibilité de stocker une table dans une variable Transact-SQL. Cette facilité est utile pour renvoyer une table à partir d’une fonction utilisateur.
Elle peut aussi être utilisée à l’intérieur d’une procédure stockée pour remplacer une table temporaire. Vous entendrez parfois dire que la variable de type table est bien plus légère qu’une table temporaire car elle n’est pas écrite dans tempdb et ne vit qu’en mémoire. C’est erroné. La variable de type table est elle aussi stockée dans tempdb, comme une table temporaire. SQL Server lui assigne un nom interne.
Il est très simple de le démontrer :
SELECT * FROM tempdb.INFORMATION_SCHEMA.TABLES;
GO
DECLARE @t TABLE (id int)
SELECT * FROM tempdb.INFORMATION_SCHEMA.TABLES;
Vous verrez dans le deuxième apparaître une nouvelle référence de table dans les métadonnées de tempdb, avec un nom ressemblant à ceci (exemple lors de notre exécution) : #04CA11FE.
Notez que si vous ne séparez pas les deux tests par un GO, vous verrez la table dans les deux SELECT, le DECLARE étant placé en premier par la compilation du code SQL.
Comme pour une table temporaire, la table contenue dans la variable réside en mémoire jusqu’au moment où elle atteint une certaine taille, elle est ensuite écrite dans tempdb.
Le gain apporté par les variables de type table est donc limité.
Y a-t-il alors une différence entre les deux options ?
Oui, la variable de type table est plus rapide principalement parce qu’elle consomme moins de ressources pour la maintenir : il n’y pas de calcul de statistiques de colonnes sur une variable de type table par exemple, le verrouillage des lignes est moindre, et ne dure que le temps de l’instruction de modification, de même que la transaction de modification, même si elle est journalisée (il suffit pour le constater d’utiliser la fonction fn_dblog() que nous avons déjà utilisée), n’est pas enrôlée dans une transaction explicite, elle s’exécute et est validée automatiquement dans sa propre transaction « privée ».
Ces avantages peuvent aussi se révéler des inconvénients, selon l’utilisation qu’on veut faire de la variable de type table.
L’absence de calcul de statistiques sur les colonnes peut être contre-productif sur des variables de type table volumineuses.
Comme l’optimiseur n’a aucune statistique, son plan d’exécution va se baser sur l’estimation du retour de zéro ou d’une seule ligne, quelle que soit la réalité.
On peut le vérifier simplement, par exemple en regardant le plan d’exécution estimé de cette requête (qui retourne en réalité 1763 lignes sur ma version de la base resources) :
DECLARE @t TABLE (Name SYSNAME)
INSERT @t
SELECT name FROM sys.system_objects
SELECT * FROM @t
Le plan d’exécution généré peut donc se révéler bien moins performant qu’avec une table temporaire.
Il est de même impossible de créer des index sur une variable (à part un index lié à une contrainte : déclaration de clé primaire ou de clé unique, possibles uniquement à la création de la table), comme il est impossible d’y appliquer après création toute commande DDL. Ainsi, les variables ne doivent pas être utilisées pour remplacer des tables temporaires volumineuses sur lesquelles on effectue beaucoup d’opérations de recherche.
Nous l’avons dit, les opérations sur la variable ne sont pas enrôlées dans une transaction.
La différence est simple à expérimenter :
USE tempdb
GO
CREATE TABLE #t (Name SYSNAME)
BEGIN TRAN
INSERT #t SELECT name FROM [master].[dbo].[sysobjects]
ROLLBACK
SELECT * FROM #t
GO
DECLARE @t TABLE (Name SYSNAME)
BEGIN TRAN
INSERT @t SELECT name FROM [master].[dbo].[sysobjects]
ROLLBACK
SELECT * FROM @t;
Dans la première partie du code, nous utilisons une table temporaire, dans laquelle nous insérons des lignes à l’intérieur d’une transaction explicite.
Après l’annulation de la transaction (ROLLBACK), la table est vide : l’insertion a été annulée.
En revanche, l’application du même code à la variable de type table montre que, même après le ROLLBACK, les lignes insérées sont toujours dans la variable.
Bien que bénéfique pour les performances, ce comportement est évidemment dangereux : si vous codez des transactions impliquant des variables de type table, vous risquez d’obtenir des résultats inattendus.
En conclusion, Microsoft recommande de remplacer les tables temporaires par des variables autant que possible. Précisons donc qu’elles ne sont intéressantes que lorsqu’elles sont de petite taille, pour des opérations simples, et bien entendu, lorsqu’on ne peut les remplacer par des jointures, des sous-requêtes ou des expressions de table.
Pour ou contre le SQL dynamique
Le sujet fait débat.
Que penser du SQL dynamique ?
C’est ainsi qu’est appelée la possibilité de générer une instruction SQL, plus ou moins complexe, dans une variable de type VARCHAR, pour ensuite l’évaluer et l’exécuter dynamiquement à l’aide du mot-clé EXEC(UTE).
Par exemple :
DECLARE @sql varchar(8000)
SET @sql = 'SELECT * FROM Person.Contact'
EXEC (@sql)
Cette syntaxe particulière est fréquemment utilisée pour construire, à l’intérieur de procédures stockées, des requêtes complexes, notamment pour permettre une combinaison de multiples critères de recherches dans la clause WHERE.
Imaginons le cas d’un site web qui permet, dans une page de formulaire, d’effectuer une recherche multi-critères sur des produits.
Chaque argument de recherche correspond à une colonne, le tout sur une ou plusieurs tables de notre base. L’internaute peut saisir ou non une valeur pour chaque argument. Une procédure stockée reçoit en paramètre la liste des arguments, qu’elle utiliser pour filtrer la requête. Il n’y a pratiquement que deux choix : écrire une requête traditionnelle qui prend en compte tous les cas de figure, comme ceci :
SELECT FirstName, MiddleName, LastName, Suffix, EmailAddress
FROM Person.Contact
WHERE
(LastName = @LastName OR @LastName IS NULL) AND
(FirstName = @FirstName OR @FirstName IS NULL) AND
(MiddleName = @MiddleName OR @MiddleName IS NULL) AND
(Suffix = @Suffix OR @Suffix IS NULL) AND
(EmailAddress = @EmailAddress OR @EmailAddress IS NULL)
ORDER BY LastName, FirstName
ou générer son code SQL de façon dynamique, avec une construction comme celle-ci :
DECLARE @sql varchar(8000)
SET @sql = '
SELECT FirstName, MiddleName, LastName, Suffix, EmailAddress
FROM Person.Contact
WHERE '
IF @FirstName IS NOT NULL
SET @sql = @sql + ' FirstName = ''' + @FirstName + ''' AND '
IF @MiddleName IS NOT NULL
SET @sql = @sql + ' MiddleName = ''' + @MiddleName + ''' AND '
IF @LastName IS NOT NULL
SET @sql = @sql + ' LastName = ''' + @LastName + ''' AND '
IF @Suffix IS NOT NULL
SET @sql = @sql + ' Suffix = ''' + @Suffix + ''' AND '
IF @EmailAddress IS NOT NULL
SET @sql = @sql + ' EmailAddress = ''' + @EmailAddress + '''
AND '
SET @sql = LEFT(@sql, LEN(@sql)-3)
EXEC (@sql)
Le SQL dynamique a ses défauts : intégré dans une procédure stockée, il annule en quelque sorte les avantages de précompilation de la procédure. En effet, la chaîne exécutée ne fait plus partie de la procédure stockée. Son évaluation et exécution dynamique sont prises en charge par le moteur relationnel comme les autres requêtes ad-hoc.
Sécurité
Une autre contrainte vient de la sécurité : le SQL dynamique n’obéit plus aux règles de chaînage de propriétaires. En d’autres termes, les privilèges doivent être vérifiés sur les objets contenus dans le SQL dynamique, et l’utilisateur exécutant la procédure doit donc être autorisé sur ces objets. Ceci pour éviter les risques d’injection SQL, c’est-à-dire d’envoi de code malicieux. Vous pouvez créer votre procédure avec la clauseEXECUTE ASpour l’exécuter dans un contexte d’utilisaeur ayant des privilèges sur ces objets. Soyez néanmoins très prudents sur les risques d’injections (voyez par exemple cet article, pour vous prévenir contre elles).
À quoi bon faire une procédure stockée si c’est pour la faire agir comme un code client ? Mais dans le cas de figure du formulaire de recherche, cet inconvénient se révèle plutôt un avantage.
La non-réutilisation du plan d’exécution permet d’éviter l’écueil dans lequel nous tombons dans le cas de l’exemple de requête statique utilisant le bricolage (LastName = @LastName OR @LastName IS NULL).
Nous avons créé deux procédures stockées dont vous trouverez le source sur le site d’accompagnement du livre.
Elles sont nommées Person.SearchContactsStatique et Person.SearchContactsDynamique, et elles implémentent la même requête selon les deux solutions proposées.
Essayons deux appels :
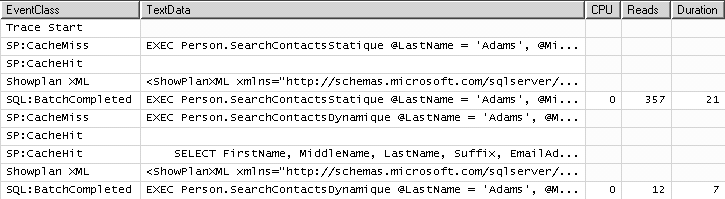
EXEC Person.SearchContactsStatique @LastName = 'Adams'
GO
EXEC Person.SearchContactsDynamique @LastName = 'Adams'
GO
EXEC Person.SearchContactsStatique @LastName = 'Adams', @MiddleName = 'S'
GO
EXEC Person.SearchContactsDynamique @LastName = 'Adams', @MiddleName = 'S'
GO
Sur la figure 8.14, nous voyons la différence de performance entre les deux solutions, lors du deuxième appel. Elle est très parlante. La solution dynamique gagne haut la main. Nous voyons aussi un CacheHit : le code ad-hoc de la requête dynamique s’est tout de même inséré dans le cache de plans.
Sur les figures 8.15 et 8.16, nous voyons respectivement le plan de la première procédure – qui n’a pas changé, et le plan de la seconde – qui s’est adapté.
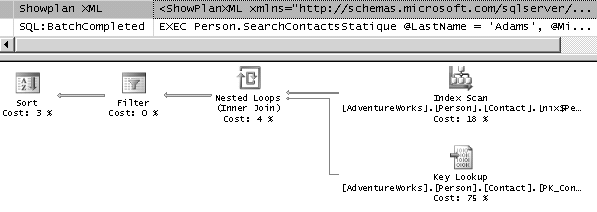
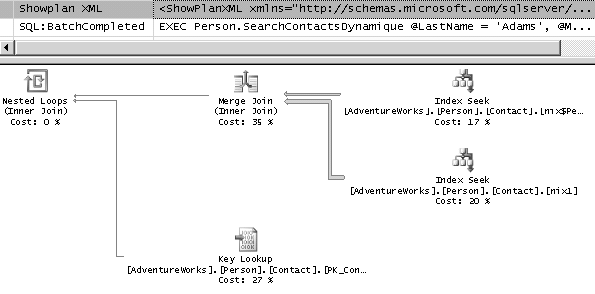
Nous pourrions conservé la syntaxe de la première procédure, et forcer la recompilation, mais la requête, comportant de multiples variables, reste difficile à analyser. Parfois, la syntaxe dynamique, malgré ses défauts, en terme de sécurité et de lisibilité, est intéressante pour les performances.
éviter les curseurs
Le curseur est une construction T-SQL permettant de traiter séquentiellement un jeu de résultat, du côté serveur.
Parce qu’il viole la syntaxe ensembliste du langage SQL, et ainsi court-circuite toute possibilité d’optimisation par SQL Server, il est l’ennemi public numéro un des performances du code SQL.
En présence de curseurs, la meilleure décision d’optimisation à prendre est de les remplacer par du code ensembliste, ce qui est la plupart du temps possible.
Bien que les curseurs soient en eux-mêmes « optimisables » (par le choix de curseurs en type READ ONLY ou FAST_FORWARD notamment), nous pensons préférable de présenter des moyens de s’en passer.
La plupart des curseurs qu’on peut rencontrer dans du code de production sont créés par manque de connaissance des possibilités du langage SQL.
Le code d’administration est un problème différent. On y rencontre des curseurs pour automatiser des maintenances sur les objets, ce qui est acceptable, compte tenu de la fréquence d’utilisation, et du choix de fenêtres d’administration favorables.
Souvent, les curseurs sont utilisés pour effectuer des traitements ou des vérifications complexes sur les lignes. Ils peuvent en général être remplacés par de simples jointures, ou un passage par une table temporaire. Le but est de les récrire en code ensembliste.
Si le traitement ligne par ligne est néanmoins nécessaire, il est souvent plus intéressant d’effectuer une boucle WHILE avec des SELECT, qui se révèlent plus efficaces.
Voici un exemple simple de curseur, et son remplacement par une boucle WHILE :
curseur :
DECLARE cur CURSOR FAST_FORWARD
FOR SELECT ContactId FROM Person.Contact ORDER BY ContactId
DECLARE @CurrentContactID int
OPEN cur
FETCH NEXT FROM cur INTO @CurrentContactID
WHILE (@@fetch_status <> -1)
BEGIN
IF (@@fetch_status <> -2)
PRINT @CurrentContactID
FETCH NEXT FROM cur INTO @CurrentContactID
END
CLOSE cur
DEALLOCATE cur
GO
Boucle WHILE :
DECLARE @CurrentContactID int
SELECT TOP 1 @CurrentContactID = ContactId
FROM Person.Contact ORDER BY ContactId
WHILE 1 = 1
BEGIN
PRINT @CurrentContactID
SELECT TOP 1 @CurrentContactID = ContactID
FROM Person.Contact
WHERE ContactID > @CurrentContactID
IF @@ROWCOUNT = 0 BREAK
END -- WHILE
Mais les boucles ne sont pas toujours nécessaires.
SQL est un langage déclaratif et ensembliste, mais l’exécution de la requête par le moteur d’exécution est au final séquentielle : il faut bien finir par parcourir les lignes l’une après l’autre.
Cette caractéristique peut être mise à profit.
Voici par exemple comment réaliser une concaténation :
DECLARE @str VARCHAR(MAX)
SELECT @str = COALESCE(@str + ', ', '') + LastName
FROM Person.Contact
GROUP BY LastName
ORDER BY LastName;
SELECT @str;
à l’aide des fonctions SQL et des jointures, vous pouvez aussi réaliser des séparations et des pivots. Par exemple :
CREATE TABLE #citations (
auteur varchar(50),
phrase varchar (1000)
);
INSERT INTO #citations
VALUES
('Guitry', 'Il y a des gens sur qui on peut compter. Ce sont généralement des gens dont on n''a pas besoin'),
('Cioran', 'Un homme ennuyeux est un homme incapable de s''ennuyer'),
('Talleyrand', 'Les mécontents, ce sont des pauvres qui réfléchissent');
SELECT
auteur,
NullIf(SubString(' ' + phrase + ' ' , id ,
CharIndex(' ' , ' ' + phrase + ' ' , id) - ID) , '') AS mot
FROM (SELECT ROW_NUMBER() OVER (ORDER BY NEWID()) as id
FROM sys.system_views) tally
CROSS JOIN #citations
WHERE id <= Len(' ' + Phrase + ' ') AND SubString(' ' + Phrase + ' ' , id - 1, 1) = ' ';
Cette requête place chaque mot rencontré dans la citation sur une nouvelle ligne, dans la colonne mots.
Elle se base sur une jointure avec une table de nombres, que nous avons ici généré à la volée.
Une table de nombre est toujours utile, faites-en une, à l’aide de ROW_NUMBER().
Pour plus de précision sur cette méthode de découpage, lisez cet article.
Un autre besoin courant est de produire des totaux cumulés.
Cette opération peut être plus rapide effectuée par un curseur que par une requête ensembliste, c’est donc un contre-exemple[^30]. Le code ensembliste est à essayer toutefois sur des petits totaux cumulés.
Voici un exemple de code :
SELECT
th1.TransactionID,
th1.ActualCost,
SUM(th2.ActualCost) AS TotalCumule
FROM Production.TransactionHistory th1
JOIN Production.TransactionHistory th2
ON th2.TransactionID <= th1.TransactionID
AND th2.TransactionDate = '20030901'
WHERE th1.TransactionDate = '20030901'
GROUP BY th1.TransactionID, th1.ActualCost
ORDER BY th1.TransactionID;
Récursivité
Avant SQL Server 2005, la récursivité ensembliste n’était pas possible (en tout cas sur des recherche récusrives dont on ne connaissait pas la profondeur). L’expression de table (Common Table Expression, CTE) résout ce problème.
Exemple d’appel récursif pour descendre dans une hiérarchie classique employé / manager :
WITH employeeCTE AS
(
SELECT e.EmployeeId, c.FirstName, c.LastName, 1 as niveau,
CAST(N'lui-même' as nvarchar(100)) as boss
FROM HumanResources.Employee e
JOIN Person.Contact c ON e.ContactID = c.ContactID
WHERE e.ManagerID IS NULL
UNION ALL
SELECT e.EmployeeId, c.FirstName, c.LastName, niveau + 1,
CAST(m.FirstName + ' ' + m.LastName as nvarchar(100))
FROM HumanResources.Employee e
JOIN Person.Contact c ON e.ContactID = c.ContactID
JOIN employeeCTE m ON m.EmployeeId = e.ManagerId
)
SELECT FirstName, LastName, niveau, boss FROM EmployeeCTE;
EN SQL Server 2008, vous disposez du type de données HierarchyID, qui est un type complexe implémenté en classe .NET.
Il permet de stocker une information de hiérarchie, et de retrouver ces informations à travers de méthodes.
Malgré le fait que ce soit un type .NET, il est plus rapide que l’utilisation de CTE.
De plus, on peut indexer ses propriétés si nécessaire, en passant par une colonne calculée.
Pour vous donner une idée de l’utilisation de ce type, voici un exemple de requête, qui fait à peu près la même chose que la CTE ci-dessus :
SELECT
o1.EmployeeName,
o1.EmployeeID.GetLevel() as level,
o2.EmployeeName as boss
FROM HumanResources.Organization o1
JOIN HumanResources.Organization o2
ON o2.EmployeeID = o1.EmployeeID.GetAncestor(1)
WHERE hierarchyid::GetRoot().IsDescendantOf(o1.EmployeeId)= 1[^31]
Vous trouvez des exemples d’utilisation dans les BOL 2008, sous l’entrée « Working with hierarchyid Data ».
Une dernière méthode, très efficace, implique une structuration de la table spécifique, en représentation intervallaire. Vous en trouvez la description dans cet article de Frédéric Brouard.
Mises à jour
Un UPDATE s’effectue lui aussi ligne par ligne, même si l’instruction est ensembliste.
Comme vous pouvez affecter une valeur à une variable dans un UPDATE, et mélanger cette affectation avec une mise à jour de colonne, vous pouvez générer une forme détournée de boucle, qui vous évitera un curseur.
Exemple très simple :
CREATE TABLE dbo.testloop (
id int NOT NULL IDENTITY (1,1) PRIMARY KEY CLUSTERED,
nombre int NULL,
groupe int NOT NULL
)
GO
INSERT INTO dbo.testloop (groupe)
SELECT TOP (10) 1 FROM sys.system_objects UNION ALL
SELECT TOP (20) 2 FROM sys.system_objects UNION ALL
SELECT TOP (15) 3 FROM sys.system_objects;
GO
DECLARE @i int = 0
UPDATE dbo.testloop
SET @i = @i + 1,
nombre = @i
GO
SELECT * FROM dbo.testloop;
Cette méthode est relativement peu sûre, car elle se base sur une implémentation physique non documentée, et potentiellement non consistante au fil des versions.
Elle est néanmoins pratique.
Depuis SQL Server 2005, les fonctions de fenêtrage permettent de réaliser la même opération, avec en plus la capacité de gérer précisément un ordre, et un regroupement par la valeur d’autres colonnes (c’est pour cette raison que nous avons créé la colonne groupe dans la table).
Le problème est que nous ne pouvons utiliser une fonction de fenêtrage que dans un SELECT.
Nous pouvons contourner cette limitation à l’aide d’une expression de table :
WITH cteTestLoop AS (
SELECT
id,
ROW_NUMBER() OVER(ORDER BY id) as rownumber
FROM dbo.testloop
)
UPDATE tl
SET nombre = ctl.rownumber
FROM dbo.testloop tl
JOIN cteTestLoop ctl ON tl.id = ctl.id;
Cet exemple effectue exactement la même mise à jour, mais avec garantie de l’ordre par la colonne id.
Cette méthode est officielle et sûre, en revanche vous pourriez encore utiliser la solution à base de variable dans les cas où le tri ne vous importe pas, pour des raisons de performance pure.
Voyez la différence de plan d’exécution sur la figure 8.17. La version CTE doit créer un plan compliqué, avec une jointure sur la même table, un tri et une table de travail (table spool).

Mais, il faut aussi dire qu’avec la fonction de partitionnement, il est facile de recommencer la numérotation à chaque groupe, en modifiant la fonction ROW_NUMBER() dans la CTE ainsi :
WITH cteTestLoop AS (
SELECT
id,
ROW_NUMBER() OVER(PARTITION BY groupe ORDER BY id) as rownumber
FROM dbo.testloop
) ...
Ce qui serait difficile à imiter dans notre « bricolage », surtout pour garantir un tri correct.
La fonction ROW_NUMBER() demande obligatoirement un ORDER BY.
Vous pouvez simplement utiliser n’importe quelle colonne, ou, si vous n’avez pas de colonne pour générer cet ordre, vous pouvez utiliser l’astuce suivante : ROW_NUMBER() OVER(ORDER BY (SELECT 0)).
Optimisez vos déclencheurs
Les déclencheurs (triggers) sont des blocs de code SQL qui sont exécutés au déclenchement d’une opération DML sur une table : INSERT, UPDATE ou DELETE.
Depuis SQL Server 2005, existent aussi des déclencheurs DDL, qui s’exécutent lors de toute modification de structures. Ils n’entrent pas dans le cadre de l’optimisation du système, nous ne les aborderons donc pas ici.
Du point de vue de la compilation, les déclencheurs se comportent comme des procédures stockées : leur plan d’exécution est mis en cache dans le cache de procédure à leur premier rappel, et réutilisé ensuite. Il n’y a donc pas recompilation systématique, sauf si le code lui-même provoque des recompilations en modifiant le contexte. Il est important de garder la code à l’intérieur du déclencheur aussi court et simple que possible : en effet, il s’exécute dans la transaction de l’instruction qui l’a déclenché, et la prolonge donc d’autant, ce qui augmente la durée des verrous.
En SQL Server, les déclencheurs sont uniquement ensemblistes (par opposition à certains SGBDR qui implémentent des déclencheurs « PER ROW »), cela veut dire qu’ils se déclenchent une seule fois par instruction, quel que soit le nombre de lignes affectées. Il est donc essentiel de penser en terme de requêtes ensemblistes dans un déclencheur.
Il est très commun de voir du code tel que celui-ci, dans un trigger :
CREATE TRIGGER atr_d\$sales_currency\$archive
ON sales.currency
AFTER DELETE
AS BEGIN
DECLARE @CurrencyCode NCHAR(3),
@Name NVARCHAR(50),
@DeletedDate smalldatetime
SELECT
@CurrencyCode = CurrencyCode,
@Name = Name,
@DeletedDate = CURRENT_TIMESTAMP
FROM Deleted;
INSERT INTO sales.currencyArchive (CurrencyCode, Name, DeletedDate)
VALUES (@CurrencyCode, @Name, @DeletedDate)
END
Bien entendu, ceci ne fonctionne correctement que si une seule ligne est supprimée.
Si toute la table sales.currency est vidée, une seule ligne sera inscrite dans la table sales.currencyArchive.
C’est une erreur fréquente, méfiez-vous en.
Dans le contexte du déclencheur, deux tables virtuelles sont disponibles, pour retrouver les lignes affectées par l’instruction : DELETED contient les lignes supprimées par un DELETE ou un UPDATE, et INSERTED les lignes ajoutées par un INSERT ou un UPDATE.
L’UPDATE est considéré logiquement comme un DELETE suivi d’un INSERT.
Ces tables virtuelles sont gérées en interne par des versions de ligne stockées dans le version store de tempdb (voir section 4.4).
De ce fait, le déclenchement d’un trigger provoquera une copie de version et de l’activité dans tempdb.
De même, ces tables virtuelles n’ont pas d’index, et les recherches se feront toujours par scan (vous verrez dans le plan d’exécution des opérateurs particuliers, avec leur coût relatif : « Inserted Scan » et « Deleted scan »). Évitez donc de les déclencheurs sur des tables massivement modifiées.
Le plan d’exécution du déclencheur est visible via l’affichage des plans dans SSMS, que ce soir le plan estimé (donc aussi via SET SHOWPLAN_XML) ou le plan réel.
En revanche, SET STATISTICS IO ON n’affiche pas les statistiques de lectures et d’écriture des tables virtuelles.
Depuis SQL Server 2005, le ROLLBACK à l’intérieur d’un trigger, pour annuler la transaction de l’instruction déclenchante, envoie une erreur 3609 dans la session, afin d’avertir l’utilisateur. Vous pouvez placer le ROLLBACK dans un bloc TRY CATCH pour éviter cette erreur.
Bonne pratique : En réalité, l’erreur 3609 en envoyée si @@TRANCOUNT est égal à 0 à la sortie du déclencheur.
Elle apparaît donc aussi si un COMMIT TRANSACTION sans BEGIN TRANSACTION est exécuté dans le trigger, ce qui est sans intérêt.
Déclencher l’erreur 3609 a aussi un sens en cas de ROLLBACK.
Il est relativement dangereux d’exécuter un ROLLBACK dans un trigger, car cette instruction annule toute la chaîne des transactions, jusqu’à la transaction la plus externe.
Ce n’est peut être pas ce que vous souhaitez, dans la mesure où vous n’avez jamais de garantie que le code déclenchant le trigger ne gère pas de transaction explicite.
De même, un ROLLBACK fermera les éventuels curseurs créés dans le code appelant, sauf s’ils sont STATIC ou INSENSITIVE et si CURSOR_CLOSE_ON_COMMIT est à OFF.
Enfin, si vous faites un ROLLBACK, n’oubliez pas de le faire suivre par un RETURN, pour éviter d’exécuter ensuite du code qui serait en dehors de la transaction, et donc validé.
Il est donc plus prudent d’effectuer le ROLLBACK dans le code appelant, ou d’utiliser le mécanisme des points de sauvegarde, à l’aide d’un SAVE TRANSACTION nom_du_point;, et ensuite d’un ROLLBACK TRANSACTION nom_du_point;, qui effectivement n’annule que cette partie de la transaction.
Un trigger est déclenché quel que soit le nombre de lignes affectées. Une instruction DML avec une clause de filtre qui ne retourne aucun match fera donc exécuter le déclencheur. Comme ceci par exemple :
DELETE FROM sales.currency WHERE CurrencyCode = 'FRF';
-- ou plus simplement :
DELETE FROM sales.currency WHERE 1 = 0;
Il est bon de tester cela au début du trigger, pour éviter l’exécution du code en pure perte.
La variable @@ROWCOUNT est disponible à l’intérieur du trigger pour cela :
ALTER TRIGGER atr_d$sales_currency2$archive
ON sales.currency2
AFTER DELETE
AS BEGIN
IF @@ROWCOUNT = 0 RETURN;
--...
Pour éviter d’exécuter le code de votre déclencheur si les colonnes qui vous intéressent ne sont même pas mises à jour, servez-vous des fonctions UPDATE() et COLUMNS_UPDATED(), qui vous indiquent quelles colonnes ont été mentionnées dans l’instruction qui déclenche le trigger.
Référez-vous au BOL pour la syntaxe de ces fonctions, mais notez qu’elles n’indiquent pas si une colonne est réellement mise à jour (si sa valeur a changé), mais si elle est mentionnée dans l’instruction DML.
Un SET NOCOUNT ON est aussi une bonne idée.
Un déclencheur, comme tout bon événement, interragit le moins possible avec la session, et principalement ne renvoie pas de jeu de résultat.
C’est inutile et dangereux pour l’application cliente, qui peut être parasitée par un recordset indésirable.
Vous pouvez désactiver le renvoi de SELECT malencontreusement présents à l’intérieur d’un trigger à l’aide de l’option de serveur 'disallow results from triggers' :
EXEC sp_configure 'show advanced options', 1;
RECONFIGURE;
EXEC sp_configure 'disallow results from triggers', 1;
RECONFIGURE;
EXEC sp_configure 'show advanced options', 0;
RECONFIGURE;
Si le but est d’afficher ou de rediriger le résultat d’une opération, songez à utiliser la clause OUTPUT, plus légère, plutôt qu’un déclencheur : disponible dans les instructions INSERT, UPDATE et DELETE, cette clause rend visible les tables virtuelles DELETED et INSERTED.
Exemple pour l’archivage :
DELETE FROM sales.currency2
OUTPUT deleted.CurrencyCode, deleted.Name, CURRENT_TIMESTAMP
INTO sales.currencyArchive;
Sans la partie INTO, OUTPUT retourne le jeu de résultat à la session.
Attention, dans ce cas il ne peut y avoir de déclencheur pour la même instruction.
Nous avons pour l’instant traité de déclencheur de type AFTER, c’est-à-dire s’exécutant après la modification de données.
Il existe un autre type de déclencheur : INSTEAD OF.
Celui-ci s’exécute non pas avant l’instruction (il n’existe pas de trigger BEFORE en SQL Server), mais à la place.
Si vous voulez que l’instruction qui a déclenché le trigger s’exécute réellement, vous devez la réécrire dans le corps du trigger, en vous basant sur le contenu des tables virtuelles.
Ce type de déclencheur est utile pour réorienter le résultat d’une instruction, ou ne traiter qu’une partie de celle-ci.
Un de ses intérêts principaux est qu’il peut être placé sur une vue, permettant alors une gestion fine des mises à jour à travers la vue.
Enfin, ajoutons que souvent les déclencheurs sont utilisés pour effectuer des contrôles de cohérence.
Autant que possible, préférez les contraintes CHECK aux triggers.
Les contraintes CHECK sont trop souvent sous-estimées.
Elles peuvent contenir des expressions complexes portant sur toutes les colonnes de la ligne.
Si vous devez effectuer des contrôles à partir de données hors de la table, vous pouvez tricher en passant par une fonction utilisateur.
Si vous devez faire des vérification sur un ensemble de lignes de la table, En revanche le déclencheur sera probablement plus optimal, de par son comportement ensembliste. La fonction utilisateur, elle, devra être appelée ligne par ligne.
Voici, par exemple, un code de trigger permettant de vérifier que des dates de validité d’historique ne se chevauchent pas (attention, ce code présuppose que les colonnes fromDate et toDate n’acceptent pas les NULL) :
ALTER TRIGGER atr_iu$sales_CurrencyHistory$checkConsistency
ON sales.CurrencyHistory
FOR INSERT, UPDATE
AS BEGIN
IF @@ROWCOUNT = 0 RETURN
SET NOCOUNT ON
IF EXISTS (
SELECT 1
FROM sales.CurrencyHistory ch WITH (READUNCOMMITTED)
JOIN inserted i
ON ch.CurrencyCode = i.CurrencyCode AND
ch.fromDate <> i.fromDate
WHERE
( ch.fromDate BETWEEN i.fromDate AND i.toDate OR
ch.toDate BETWEEN i.fromDate AND i.toDate ) OR
( i.fromDate BETWEEN ch.fromDate AND ch.toDate OR
i.toDate BETWEEN ch.fromDate AND ch.toDate )
)
BEGIN
RAISERROR ('Des dates d''historique se chevauchent !', 16, 10)
RETURN
END
END
Limiter les pollings avec les notifications de requête
Si vous utilisez le client natif SQL (SQL Native Client, ou SNAC - SQLNCLI), vous pouvez profiter de la fonctionnalité de notifications de requêtes (Query Notifications). Elle est très utile pour mettre à jour automatiquement les données de référence dans votre application ou code site web. Souvent, des données de références sont chargées dans des objets de l’application client.
Ces données de références changent rarement, mais pour être sûr d’être à jour, le code client effectue des requêtes régulières de vérification, au cas où le contenu de la table aurait changé.
Query Notifications est basé sur Service Broker, et permet aux applications de s’abonner à des événements qui lui seront envoyés par le serveur, à travers le client natif.
Le code client doit simplement utiliser un objet SqlDependency, sur lequel il place un gestionnaire d’événement.
Vous trouverez plus d’informations dans les BOL, sous l’entrée « Using Query Notifications ».