Architecture de SQL Server
28 minutes à lire
Objectifs
Afin d’obtenir de bonnes performances, il est naturellement important de connaître le logiciel que nous utilisons. SQL Server est un Système de Gestion de Bases de Données Relationnelles (SGBDR) qui à la fois respecte les standards de ce type d’outils, et offre des implémentations particulières. Nous allons voir sur quelles briques logicielles SQL Server est bâti, ce qui nous permettra ensuite de mettre en place des solutions d’optimisation en toute connaissance de cause.
Architecture générale
SQL Server est un Système de Gestion de Base de Données Relationnelles (SGBDR). Il partage avec ses concurrents une architecture standardisée, fruit de décennies de recherches en ingénierie logicielle, menées par des chercheurs comme Edgar Codd, bien sûr, Chris Date et Peter Chen pour le modèle relationnel, mais aussi Michael Stonebreaker et d’autres pour différentes méthodologies et algorithmes.
Un SGBDR est en général une application client-serveur : un serveur centralisé abrite le SGBDR lui-même, dont la responsabilité est d’assurer le stockage des données, et de répondre aux demandes des clients.
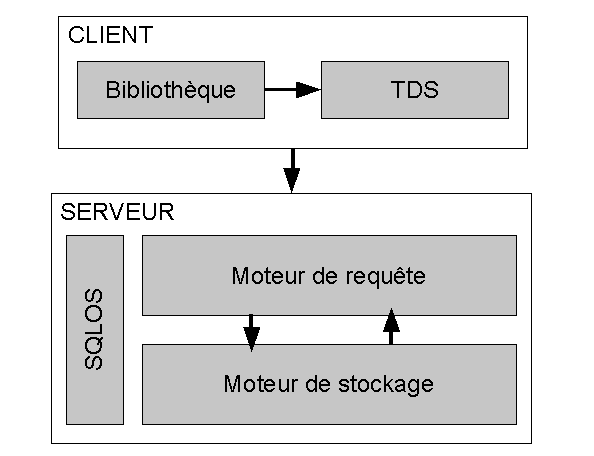
Dans le schéma figure 2.1 extrêmement simplifié, nous avons un résumé de l’architecture client-serveur de SQL Server. Une application cliente (comme SQL Server Management Studio – SSMS) envoie des requêtes en SQL. L’unique manière d’obtenir des données est de passer par le langage SQL. SQL Server n’est pas un serveur de fichier, il stocke et protège ses données à l’aide de ses mécanismes internes, et n’offre aucun moyen d’accéder directement aux données des bases. La seule façon d’obtenir des lignes de table est d’en faire la demande au serveur, à l’aide d’ordres SQL.
Ces ordres sont transmis par une bibliothèque cliente, parmi lesquelles ODBC, OLEDB ou ADO.NET, dont la tâche est de faire la transition entre les langages procéduraux clients et les bibliothèques de bas niveau en offrant une couche d’abstraction. Cette bibliothèque adresse la requête à une bibliothèque réseau (net-library) adaptée aux protocoles réseaux utilisés (de nos jour, principalement TCP-IP), qui elle-même la transmet par paquets à travers la couche physique codé dans le protocole réseau de SQL Server, nommé TDS (Tabular Data Stream), un protocole initialement développé par Sybase1 et que SQL Server partage avec ce SGBDR (bien que l’implémentation particulière de Microsoft soit nommée MS-TDS2).
Du côté serveur, SQL Server est composé de deux principaux moteurs, respectivement le moteur relationnel, relational engine (ou moteur de requête, query engine), et le moteur de stockage, storage engine, qui contiennent chacun différents modules. La requête provenant du client est prise en charge par le moteur relationnel, qui évalue le code SQL, vérifie les métadonnées et les privilèges, passe par une phase d’optimisation pour produire un plan d’exécution (query plan) optimisé, et gère l’exécution de la requête.
Les ordres d’extraction ou d’écriture proprement dits sont envoyés au moteur de stockage, dont la responsabilité est, outre de lire et écrire les pages de données, de gérer aussi la cohérence transactionnelle, notamment à travers le verrouillage. Toute la communication entre SQL Server et le serveur physique sur lequel il est installé est prise en charge par une couche d’abstraction nommée SQLOS (OS pour Operating System), une sorte de système d’exploitation intégré dans le moteur, dont nous reparlerons plus loin dans ce chapitre.
La séparation des rôles entre moteur relationnel et moteur de stockage est une constante dans les architectures des SGBDR, certains permettent même le choix entre différents moteurs de stockage, comme MySQL.
Nomenclature SQL Server Il est utile de spécifier ici les termes utilisés dans le cadres d’un serveur SQL Server. Il est par exemple à noter que les différents termes peuvent sembler troublants pour un développeur habitué à Oracle, car la nomenclature d’Oracle est sensiblement différente de celle de SQL Server. Un serveur SQL est un service Windows, qui est appelé une instance. Ainsi, chaque installation de SQL Server sur une même machine crée une nouvelle instance. Une seule instance par défaut est possible par serveur, ensuite, les autres instance sont appelées « instances nommées ». Il est ainsi possible d’installer des versions et des éditions différentes sur la même machine. Ensuite, une même instance peut comporter un grand nombre de bases de données, qui sont fortement isolées les unes des autres, notamment du point de vue de la sécurité. Ces bases de données contiennent des schémas, qui sont des conteneurs logiques conformes à la norme SQL, et ne sont en rien liés à des structures physiques de stockage ou a des utilisateurs de la base. Un objet tel qu’une table, une vue, une procédure stockée, etc. appartient à un et à un seul schéma.
Les structures de stockage
Le défi des SGBDR comme SQL Server est d’assurer les meilleures performances possibles à l’écriture et à la lecture de larges volumes de données. Pour ce faire, chaque éditeur soigne son moteur de stockage avec d’autant plus de sérieux que l’accès aux disques durs, quelque soit leurs spécifications, est l’élément le plus lent d’un système informatique.
Pour assurer ce stockage de façon optimale, SQL Server utilise deux types de fichiers différents : fichiers de données et fichiers de journal de transaction.
Fichiers de données
Les fichiers de données offrent un stockage structuré organisé selon un modèle schématisé dans la figure 2.2. Un groupe de fichiers peut contenir un ou plusieurs fichiers, qui eux-mêmes contiennent des pages de données ou d’index, regroupés dans des extensions (extents).

Le groupe de fichiers est un contenu logique, qui fonctionne comme destination implicite ou explicite d’objets (partitions, tables, index).
Lorsque vous créez une table ou un index, vous pouvez choisir le groupe de fichiers dans lequel il sera stocké.
Une base de données comporte au minimum un groupe de fichiers, créé automatiquement au CREATE DATABASE.
Ce groupe s’appelle PRIMARY, et il recueille les tables de catalogue (tables système de métadonnées).
Il ne peut donc pas être supprimé.
Chaque base a un groupe de fichiers par défaut dans lequel sera créé tout objet si aucun autre groupe de fichiers n’est explicitement spécifié dans l’ordre de création.
Ce groupe de fichier par défaut peut-être changé, avec la commande :
ALTER DATABASE nom_de_la_base
MODIFY FILEGROUP [nom_du_groupe_de_fichiers] DEFAULT;
Les commandes pour connaître le groupe de fichiers par défaut sont :
SELECT *
FROM sys.filegroups
WHERE is_default = 1;
ou
SELECT FILEGROUPPROPERTY('PRIMARY', 'IsDefault')
Un groupe de fichiers peut comporter un ou plusieurs fichiers. Il s’agit simplement de fichiers disque, qui indiquent l’emplacement physique du stockage. Si le groupe de fichiers est multifichiers, SQL Server y gère les écritures à la manière d’un RAID 1 logiciel, en simple miroir. Le contenu est donc réparti plus ou moins également entre les différents fichiers.
Les objets (tables et index) sont donc attribués à des groupes de fichiers. La répartition des données s’effectue dans des pages de 8 Ko, composées d’un en-tête de 96 octets et d’un corps contenant des lignes de table ou des structures d’index. Une page peut stocker 8 060 octets de données (8 192 – 96 – un peu de place laissée par sécurité)
La page est l’unité minimale de lecture/écriture de SQL Server. En d’autres termes, lorsque le moteur de stockage écrit sur le disque, il ne peut écrire moins qu’une page, lorsqu’il lit, il ne peut lire moins qu’une page. L’impact sur les performances est simple : plus vos lignes sont compactes (peu de colonnes, avec un type de données bien choisi), plus elles pourront résider dans la même page, et moins le nombre nécessaire de pages pour conserver la table sera élevé.
Toutes les informations d’entrées-sorties retournées par le moteur de stockage (notamment dans le cas de récupérations de statistiques IO via la commande
SET STATISTICS IO ONde la session3) sont exprimées en pages. Cette commande de session permet l’affichage de statistiques d’entrées/sorties après chaque instruction SQL. Elle est très utile pour juger du coût d’une requête. Nous en détaillons l’utilisation à la section 5.1.
Donc, SQL Server lit une page, pas moins, et une page contient une ou plusieurs lignes, mais une ligne doit résider toute entière dans la page. Cela signifie que la somme de la taille nécessaire au stockage de chaque colonne ne peut dépasser 8 060 octets, sauf exceptions qui suivent. Que se passe-t-il si la taille d’une ligne dépasse légèrement la moitié de la taille de la page ?
Tout à fait comme lorsque vous essayez de placer dans une boîte deux objets qui n’y tiennent pas ensemble : vous devez acheter une seconde boîte, et y placer un objet dans chacune, laissant une partie de l’espace de la boîte inutilisée. C’est ce qu’on appelle la fragmentation interne, et cela peut donc constituer une augmentation de taille de stockage non négligeable sur les tables volumineuses, ainsi que diminuer les performances de lectures de données.
Les extensions permettent de gérer l’allocation de l’espace du fichier. Elles contiennent 8 pages contiguës, et sont donc d’une taille de 64 Ko. Pour ne pas laisser trop d’espace inutilisé, SQL Server partage les petites tables dans une même extension, appelée « extension mixte ». Lorsque la taille de la table dépasse les 8 pages, de nouvelles extensions (extensions uniformes) sont allouées uniquement à cette table. Un désordre des pages dans les extensions entraîne une fragmentation externe. Comme un ordre particulier des lignes dans les pages, et des pages dans les extensions n’a de sens que pour une table ordonnée par un index clustered, nous traiterons des problématiques de fragmentation dans le chapitre consacré aux index.
Un fichier de données étant composé de pages, et seulement de pages, elles ne stockent pas uniquement le contenu de tables et d’index, bien que ce soit de très loin leur utilisation la plus fréquente. Quelques autre types existent, que vous pourrez voir apparaître de temps en temps, principalement dans les résultats de requêtes sur les vues de gestion dynamique. Vous trouvez leur description dans les BOL, sous l’entrée Pages and Extents. Ces ont principalement des pages de pointage et d’information sur les structures : SPF, IAM, GAM, SGAM. Elles couvrent un certain nombre de pages ou d’étendues (cette quantité étant nommée une intervalle). Les pages SPF couvrent 8 088 pages (environ 64 MO), les pages GAM, SGAM et IAM couvrent 64 000 extensions (environ 4 GO). Sans entrer dans les détails4, voici leur signification :
SPF – Page Free Space : contient un octet d’information par page référencée, indiquant notamment si la page est libre ou allouée, et quel est son pourcentage d’espace libre ;
GAM – Global Allocation Map : contient un bit par extension, qui indique si elle est libre (1) ou déjà allouée (0) ;
SGAM – Shared Global Allocation Map : contient un bit par extension, qui indique si elle est une extension mixte qui a au moins une page libre (1), ou si elle est une extension uniforme, ou qui n’a pas de page libre (0) ;
IAM – Index Allocation Map : indique quelles pages appartiennent à un objet dans un intervalle GAM.
La combinaison des informations contenues dans les pages de GAM, SGAM, IAM et SPF permet à SQL Server de gérer au mieux l’allocation des pages et extensions dans le fichier de données.
Afficher le contenu des pages
La structure détaillée des pages et du stockage des index et des tables à l’intérieur n’est en général pas déterminant pour les performances.
Nous reviendrons sur certains aspects importants au fil de l’ouvrage.
Sachez toutefois que vous pouvez inspecter le contenu des pages à l’aide d’une commande non documentée : DBCC PAGE.
Elle est utile pour se rendre compte de la façon dont travaille le moteur de stockage, et pour expérimenter certains aspects du fonctionnement de SQL Server.
Nous utiliserons cette commande dans le livre, notamment au chapitre 6.
La syntaxe de DBCC PAGE est la suivante :
DBCC PAGE ( {'dbname' | dbid}, filenum, pagenum [,printopt={0|1|2|3} ])
où filenum est le numéro de fichier et pagenum le numéro de page, que vous trouvez dans d’autres commandes en général non documentées, qui vous retourne un pointeur vers une page dans le format #:#.
Par exemple 1:543 veut dire la page 543 dans le fichier 1.
printopt permet d’indiquer le détail d’informations à retourner :
0 – en-tête de la page ;
1 – contenu détaillé incluant la table d’offset (row offset array, ou offset table, l’adresse des lignes dans la page) ;
2 – comme un, à la différence que le contenu est retourné en un dump hexadécimal ;
3 – retourne l’en-tête, plus le contenu de la page en format tabulaire (jeu de résultat) pour les index, ou détaillé pour le contenu de tables.
Le résultat de DBCC PAGE est envoyé par défaut dans le journal d’erreur de SQL Server (le fichier errorlog, qu’on trouve dans le répartoire de données de SQL Server, dans le sous-répertoire LOG).
Pour retourner le résultat dans la session, vous devez activer le drapeau de trace5 3604 :
DBCC TRACEON (3604)
DBCC PAGE supporte aussi l’option WITH TABLERESULTS, qui vous permet de retourner le résultat en format table.
Le résultat d’une commande DBCC n’est pas aisé à manipuler par code, une syntaxe telle que INSERT INTO …
CREATE TABLE #dbccpage (ParentObject sysname, Object sysname, Field
sysname, Value sysname)
GO
INSERT INTO #dbccpage
EXEC ('DBCC PAGE (AdventureWorks, 1, 0, 3) WITH TABLERESULTS');
GO
SELECT * FROM #dbccpage
Vous pouvez, grâce à DBCC PAGE, observer la structure d’allocation dans les fichiers de données.
Dans l’en-tête retournée par DBCC PAGE, vous trouvez l’indication des pages de PFS, GAM et SGAM qui référencent la page.
Au début de chaque intervalle GAM, vous trouvez une extension GAM qui ne contient que des pages de structure.
La première extension d’un fichier est une extension GAM, qui contient en page 0 l’en-tête de fichier, en page 1 la première page PFS, en page 2 la première page GAM, etc.
Mais, tout cela nous pouvons le découvrir en utilisant DBCC PAGE.
Observons la première page du fichier :
DBCC PAGE (AdventureWorks, 1, 0, 3)
Dans l’en-tête de la page, nous récupérons les informations d’allocation :
Allocation Status
GAM (1:2) = ALLOCATED SGAM (1:3) = NOT ALLOCATED PFS (1:1) = 0x44
ALLOCATED 100_PCT_FULL
DIFF (1:6) = CHANGED ML (1:7) = NOT MIN_LOGGED
Plus loin, nous pouvons observer les informations contenues dans l’en-tête. Par exemple :
FileGroupId = 1
FileIdProp = 1 Size = 30816 MaxSize = 65535
Growth = 2048
...
MinSize = 15360 Status = 0 UserShrinkSize = 65535
Nous savons donc quelle est la première page de PFS : 1:1. Un DBCC PAGE nous liste ensuite les pages qu’elle référence, avec pour chacune l’indication de sa nature : IAM ou non.
Extrait du résultat :
(1:651) - = ALLOCATED 0_PCT_FULL Mixed Ext
(1:652) - = ALLOCATED 0_PCT_FULL IAM Page Mixed Ext
(1:653) - = ALLOCATED 0_PCT_FULL Mixed Ext
(1:654) - (1:655) = ALLOCATED 0_PCT_FULL IAM Page Mixed Ext
La page 652 est donc une page IAM. Allons voir :
[...
Metadata: AllocUnitId = 72057594052083712
Metadata: PartitionId = 72057594045726720 Metadata: IndexId = 1
Metadata: ObjectId = 402100473 m_prevPage = (0:0) m_nextPage = (0:0)
pminlen = 90 m_slotCnt = 2 m_freeCnt = 6
m_freeData = 8182 m_reservedCnt = 0 m_lsn = (37:4181:117)
[...
IAM: Single Page Allocations \@0x6105C08E
Slot 0 = (1:653) Slot 1 = (0:0) Slot 2 = (0:0)
Slot 3 = (0:0) Slot 4 = (0:0) Slot 5 = (0:0)
Slot 6 = (0:0) Slot 7 = (0:0)
IAM: Extent Alloc Status Slot 1 \@0x6105C0C2
(1:0) - (1:8456) = NOT ALLOCATED
(1:8464) - (1:8496) = ALLOCATED
(1:8504) - (1:8672) = NOT ALLOCATED
(1:8680) - = ALLOCATED
(1:8688) - (1:30808) = NOT ALLOCATED
La page IAM contient un tableau d’allocation de l’extension, et pour chaque page de l’extension, le détail des pages allouées. Dans notre exemple, une seule page de l’extension est allouée à l’objet. On comprend donc qu’il s’agit d’une extension mixte. Plus loin, nous avons le détail des pages et extensions allouées à la table. Nous prendrons un exemple plus détaillé sur le sujet dans le chapitre traitant des index, afin de comprendre leur structure.
Journal de transactions
Le journal de transactions (transaction log) est un mécanisme courant dans le monde des SGBD, qui permet de garantir la cohérence transactionnelle des opérations de modification de données, et la reprise après incident.
Vous pouvez vous reporter à la section 7.5 pour une description détaillée des transactions.
En un mot, toute écriture de données est enrôlée dans une transaction, soit de la durée de l’instruction, soit englobant plusieurs instructions dans le cas d’une transaction utilisateur déclarée à l’aide de la commande BEGIN TRANSACTION.
Chaque transaction est préalablement enregistrée dans le journal de transactions, afin de pouvoir être annulée ou validée en un seul bloc (propriété d’atomicité de la transaction) à son terme, soit au moment où l’instruction se termine, soit dans le cas d’une transaction utilisateur, au moment d’un ROLLBACK TRANSACTION ou d’un COMMIT TRANSACTION.
Toute transaction est ainsi complètement inscrite dans le journal avant même d’être répercutée dans les fichiers de données.
Le journal contient toutes les informations nécessaires pour annuler la transaction en cas de rollback (ce qui équivaut à défaire pas à pas toutes les modifications), ou pour la rejouer en cas de relance du serveur (ce qui permet de respecter l’exigence de durabilité de la transaction).
Le mécanisme permettant de respecter toutes les contraintes transactionnelles est le suivant : lors d’une modification de données (INSERT ou UPDATE), les nouvelles valeurs sont inscrites dans les pages du cache de données, c’est-à-dire dans la RAM.
Seule la page en cache est modifiée, la page stockée sur le disque est intouchée.
La page de cache est donc marqué « sale » (dirty), pour indiquer qu’elle ne correspond plus à la page originelle.
Cette information est consultable à l’aide de la colonne is_modified de la vue de gestion dynamique (DMV) sys.dm_os_buffer_descriptors :
SELECT * FROM sys.dm_os_buffer_descriptors WHERE is_modified = 1
La transaction validée est également maintenue dans le journal. À intervalle régulier, un « point de contrôle » (checkpoint) aussi appelé point de reprise, est inscrit dans le journal, et les pages modifiées par des transactions validées avant ce checkpoint sont écrites sur le disque.
Les vues de gestion dynamique
À partir de la version 2005 de SQL Server, vous avez à votre disposition, dans le schéma sys, un certain nombre de vues systèmes qui portent non pas sur les métadonnées de la base en cours, mais sur l’état actuel du SGBD. Ces vues sont nommées « vues de gestion dynamiques » (dynamic management views, DMV*)*. Elles sont toutes préfixées par
dm_. Vous les trouvez dans l’explorateur d’objets, sous vues / vues système, et vous pouvez en obtenir la liste à l’aide des vues de métadonnées, par exemple ainsi :
SELECT *
FROM sys.system_objects
WHERE name LIKE 'dm_%' ORDER BY name;
Vous y trouverez la plupart des vues disponibles. Certaines n’y figurent pas car elles sont non documentées, ou sont implémentées sous forme de fonctions.
Les données retournées par ces vues dynamiques sont maintenues dans un cache spécial de la mémoire adressée par SQL Server. Elles ne sont pas persistées sur le disque. Les compteurs sont donc remis à zéro lors du redémarrage du service SQL. Par conséquent, pour que ces vues vous offrent des informations utiles, vous ne devez les consulter qu’après un temps significatif d’utilisation du serveur. Nous utiliserons beaucoup les vues de gestion dynamiques tout au long de cet ouvrage.
Checkpoint et recovery
Comment garantir la cohérence d’une base de données en cas de panne ou de redémarrage intempestif ?
Les techniques appliquées dans SQL Server sont également standards aux SGBDR. Premièrement, le maintien de toutes les informations de transaction dans le journal, avec les marqueurs temporels de leur début et fin, assure qu’elles puissent être rejouées. Lorsque l’instance SQL redémarre, chaque base de données entre en étape de récupération (recovery) : les transactions du journal non encore répercutées dans les pages de données sont rejouées. Ce sont soit des transactions qui n’étaient pas terminées lors du dernier checkpoint, soit qui ont commencé après celui-ci. Si la transaction n’est pas validée dans le journal (parce qu’elle a été annulée explicitement, ou parce qu’elle n’a pas pu se terminer au moment de l’arrêt de l’instance), elle est annulée. Selon le volume des transactions journalisées et la date du dernier checkpoint, cette récupération peut prendre du temps. SQL Server s’assure donc d’émettre un point de contrôle suffisamment souvent pour maintenir une durée de récupération raisonnable.
Une option de l’instance permet de régler la durée maximum, en minutes, de la récupération : le recovery interval.
Par défaut la valeur est 0, ce qui correspond à une auto-configuration de SQL Server pour assurer dans la plupart des cas une récupération de moins d’une minute.
Changer cette valeur diminue les fréquences de checkpoint et augmente le temps de récupération.
Vous pouvez le faire dans les propriétés de l’instance dans SSMS, ou via sp_configure :
EXEC sp_configure 'show advanced option', '1';
RECONFIGURE;
EXEC sp_configure 'recovery interval', '3';
RECONFIGURE WITH OVERRIDE;
EXEC sp_configure 'show advanced option', '1';
La procédure stockée système sp_configure est utilisée pour modifier des options de configuration de l’instance SQL Server.
Certaines options sont aussi visibles dans les boîtes de dialogues de configuration dans SSMS.
Par défaut, sp_configure ne touche que les options courantes.
Pour afficher et changer les options avancées, vous devez utiliser sp_configure lui-même pour les activer avec sp_configure 'show advanced option', '1' .
La fréquence d’exécution des checkpoints est donc calculée par rapport à cet intervalle, et selon la quantité de transactions dans le journal. Elle sera basse pour une base principalement utilisé pour la lecture, et de plus en plus haute selon le volume de modifications. Vous n’avez généralement pas besoin de modifier cette option. Si vous faites l’expérience de pointes d’écriture sur le disque de données, avec une file d’attente qui bloques d’autres lectures / écritures, et seulement dans ce cas, vous pouvez songer à l’augmenter, par exemple à cinq minutes, en continuant à surveiller les compteurs de disque, pour voir si la situation s’améliore. Nous reviendrons sur ces compteurs dans la section 5.3 concernant le moniteur système.
La conservation des transactions dans le journal après checkpoint est contrôlée par l’option de base de données appelée « mode de récupération » (recovery model). Elle est modifiable par la fenêtre de propriétés d’une base de données dans SSMS, ou par la commande :
ALTER DATABASE [base] SET RECOVERY { FULL | BULK_LOGGED | SIMPLE }
Les trois options modifient le comportement du journal de la façon suivante :
FULL — toutes les transactions sont conservées dans le journal, en vue de leur sauvegarde. Cette option n’est donc à activer que sur les bases de données pour lesquelles on veut pratiquer une stratégie de sauvegarde impliquant des sauvegardes de journaux. Seule cette option, alliée aux sauvegardes, permet de réaliser des restaurations à un point dans le temps. Si le journal n’est pas sauvegardé, le fichier grandira indéfiniment pour conserver toutes les transactions enregistrées ;
BULK_LOGGED — afin de ne pas augmenter exagérément la taille du journal, les opérations en lot (
BULK INSERT,SELECT INTO,CREATE INDEX…) sont journalisées de façon minimale, c’est-à-dire que leurs transactions ne sont pas enregistrées en détail. Seules les adresses de pages modifiées sont inscrites dans le journal. Lors de la sauvegarde de journal, les extensions modifiées sont ajoutées à la sauvegarde. Si une sauvegarde de journal contient des modifications en lot, la sauvegarde ne pourra pas être utilisée pour une restauration à un point dans le temps ;SIMPLE — dans le mode simple, le journal de transactions est vidé de son contenu inutile (ce qu’on appelle la portion inactive du journal) après chaque checkpoint. Aucune sauvegarder de journal n’est donc possible. En revanche, la taille du journal restera probablement raisonnable.
En SQL Server, le journal de transactions consiste en un ou plusieurs fichiers, au remplissage séquentiel, dans un format propriétaire complètement différent des fichiers de données. Ce format n’est pas publié par Microsoft, ce qui fait qu’il n’y a pas réellement de méthode officielle pour en lire le contenu et en retirer des informations exploitables. Il est également impossible de récupérer ou annuler une transaction validée à partir du journal. Il est en revanche possible de faire des sauvegardes de journal et de les restaurer à un point dans le temps, annulant ainsi toutes les transactions validées à cet instant.
Le journal de transactions est donc une chaîne séquentielle d’enregistrements de transactions, comportant toutes les informations nécessaires à une réexécution de la transaction par le système lors d’une phase de restauration ou de récupération, ainsi qu’un numéro de séquence d’enregistrement, le log sequence number, ou LSN. Une restauration de journal peut également être effectuée jusqu’à un LSN. Encore faut-il savoir quel est le LSN d’une opération recherchée. Nous l’avons dit, le format du journal n’est pas connu. Il n’y a que deux manières de lire ce journal de transactions : acheter un logiciel tiers, ou utiliser des instructions SQL Server non documentées.
Afficher le contenu du journal de transactions
ceci est obsolète Quelques éditeurs, dont le plus connu est Lumigent, avec son outil nommé « Log Explorer », ont déchiffré, avec des méthodes de reverse engineering, le format du journal, et proposent des outils plus ou moins puissants pour voir et utiliser le contenu du journal et le détail des opérations effectuées par chaque transaction.
SQL Server comporte également quelques commandes non documentées – c’est-à-dire cachées, et susceptibles d’être modifiées ou retirées sans préavis dans des versions suivantes du produit – qui affichent des informations sur le journal.
La plus complète est une fonction système, sys.fn_dblog (ou ::fn_dblog), que vous pouvez appeler ainsi dans le contexte de la base de données désirée :
SELECT * FROM sys.fn_dblog(DB_ID(),NULL)
Cette vue vous retourne les informations de LSN, le type d’opération effectuée, l’identifiant de transaction, et plusieurs éléments intéressants, comme le nom de l’unité d’allocation (la table ou l’index affecté), le nombre de verrous posés, etc.
Manque seulement le détail des modifications, qui pourrait servir à savoir en détail ce qui s’est produit.
Chaque ligne comporte une colonne nommée « Previous LSN », qui permet de suivre l’ordre des instructions d’une même transaction.
Le type d’instruction est assez clair, comme par exemple LOP_BEGIN_XACT, LOP_MODIFY_ROW et LOP_COMMIT_XACT.
Cette fonction peut être utile pour obtenir le détail transactionnel d’une opération.
Prenons un exemple.
Nous chercherons d’abord à obtenir un journal aussi vide que possible.
Nous mettons donc la base de données en mode simple, et nous provoquons manuellement un CHECKPOINT.
ALTER DATABASE AdventureWorks SET RECOVERY SIMPLE;
GO
CHECKPOINT;
En exécutant la fonction fn_dblog(), nous constatons que le journal est pratiquement vide.
Effectuons une modification simple dans la table Sales.Currency, qui contient les références de devises :
UPDATE Sales.Currency
SET Name = Name
WHERE CurrencyCode = 'ALL'
La modification demandée ne réalise aucun changement.
SQL Server va-t-il tout de même faire un UPDATE ?
Grâce à fn_dblog() nous constatons que non.
Une seule opération est journalisée, de type LOP_SET_BITS, une mise à jour des informations d’une page, pas de son contenu.
Essayons maintenant de réellement changer quelque chose :
UPDATE Sales.Currency
SET Name = 'Lek2'
WHERE CurrencyCode = 'ALL'
Les opérations suivantes sont inscrites dans le journal :
| Operation | Context | AllocUnitName |
|---|---|---|
| LOP_BEGIN_XACT | LCX_NULL | NULL |
| LOP_MODIFY_ROW | LCX_CLUSTERED | Sales.Currency.PK_Currency_CurrencyCode |
| LOP_SET_BITS | LCX_DIFF_MAP | Unknown Alloc Unit |
| LOP_DELETE_ROWS | LCX_MARK_AS_GHOST | Sales.Currency.AK_Currency_Name |
| LOP_SET_BITS | LCX_PFS | Sales.Currency.AK_Currency_Name |
| LOP_INSERT_ROWS | LCX_INDEX_LEAF | Sales.Currency.AK_Currency_Name |
| LOP_COMMIT_XACT | LCX_NULL | NULL |
Ici les opérations sont claires : modification de la ligne (LOP_MODIFY_ROW sur l’index clustered, donc sur la table), et ensuite opération de suppression puis d’insertion dans l’index AK_Currency_Name, qui contient la colonne modifiée dans sa clé.
Vous verrez parfois l’UPDATE journalisé non comme un LOP_MODIFY_ROW, mais comme un couple de LOP_DELETE_ROWS et LOP_INSERT_ROWS, car SQL Server gère deux types de mises à jour : l’update direct et l’update différé (deferred), selon les cas.
L’update différé correspond donc à une suppression de ligne suivie d’un ajout de ligne.
C’est par exemple le cas lorsque la mise à jour augmente la taille de la ligne et la force à être déplacée dans une autre page de données.
Taille des fichiers
Physiquement, le journal est composé de « fichiers virtuels de journal » (virtual log files, ou VLF), qui sont des blocs logiques dans le même fichier de journal, de taille et de nombre variables. SQL Server essaie de conserver un nombre limité de VLFs, car cela a un impact sur les performances. Lorsque le journal augmente de taille automatiquement, le nombre de VLF augmente et est plus important que si la taille avait été prévue correctement dès le départ. Ne soyez donc pas trop avare d’espace à la création de vos bases de données.
On peut maintenir plusieurs fichiers de journal sur la même base de données. Cela ne constituera pas une optimisation de performances par parallélisation des écritures, car, nous l’avons vu, le journal de transactions est par nature séquentiel. Chaque fichier sera utilisé à tour de rôle, SQL server passant au fichier suivant lorsque le précédent sera plein. Cela ne sera donc utile que pour pallier à un manque d’espace sur des disques durs de petite taille.
SQLOS
Si vous voulez obtenir les meilleures performances de votre serveur SQL, la chose la plus importante en ce qui concerne le système lui-même, est de la dédier à SQL Server. La couche représentée par le système d’exploitation lui-même, et les autres applications s’exécutant en concurrence, doit être réduite au maximum, en désactivant par exemple les services inutiles. SQL Server est livré avec d’autres services, notamment toute la partie Business Intelligence, qui fait appel à des moteurs différents : Analysis Service est un produit conceptuellement et physiquement tout à fait séparé du moteur relationnel, de même que Reporting Services utilise des technologies qui entrent en concurrence avec SQL Server (en version 2005, Reporting Services se base sur IIS, le serveur web de Microsoft, qui ne fait notoirement pas bon ménage avec SQL Server, en terme de performances, s’entend. En SQL Server 2008, il est plus intégré et utilise notamment SQLOS). Il est essentiel de déplacer ces services sur des serveurs différents de ceux que vous voulez dédier aux performances de SQL server, c’est-à-dire de la partie relationnelle, dont le travail de base est de stocker et de service de l’information avec la vélocité et la cohérence maximales. Un serveur est une ville trop petite pour deux personnalités comme SQL Server.
Bien que SQL Server soit étroitement lié au système d’exploitation Windows, il ne se repose pas, comme la quasi-totalité des applications utilisateurs, sur toutes ses fonctionnalités d’accès et de partage des ressources système. Les recherches en bases de données, un domaine actif depuis longtemps, montrent que les meilleures performances sont atteintes en laissant le soin au SGBDR de gérer certaines parties de ce qui est traditionnellement de la responsabilité du système d’exploitation. Oracle, par exemple, cherche depuis longtemps à minimiser le rôle de l’OS, en contournant les systèmes de fichiers journalisés à l’aide de raw devices (Oracle directIO), en proposant un outil comme ASM (Automatic Storage Manager) pour gérer directement le système de fichiers, ou en intégrant depuis peu sa propre couche de virtualisation, basée sur Xen.
SQL Server n’échappe pas à cette règle. Il intègre sa couche de gestion de fonctionnalités bas niveau, nommée SQLOS (pour SQL Server Operating System). Elle prend en charge des fonctionnalités d’ordonnancement des threads de travail, la gestion de la mémoire, la surveillance des ressources, les entrées / sorties, la synchronisation des threads, la détection des deadlocks, etc. qui permettent de gérer à l’intérieur même de SQL Server, proche des besoins du moteur, les éléments essentiels à un travail efficace avec les ressources de la machine[^6]. Vous trouvez un schéma des différents modules présents dans SQLOS en figure 2.3.
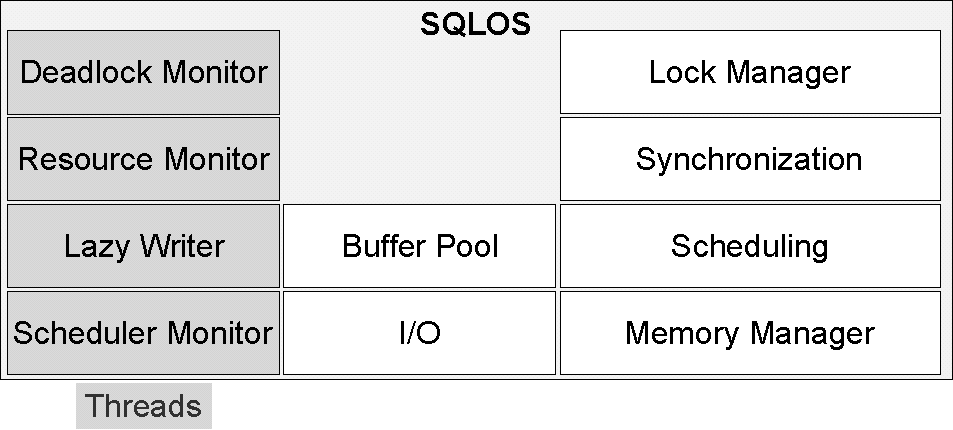
Vous pouvez observer l’activité de SQLOS à l’aide de vues de gestion dynamique préfixées par sys.dm_os_.
Les vues de gestion dynamique (dynamic management views, DMV) sont des vues qui retournent des informations sur l’état du système, et non sur des données ou des métadonnées stockées dans une base.
SQLOS permet de gérer efficacement le multiprocessing.
Un ordonnanceur (scheduler) est lié à chaque processeur physique, qui gère à l’intérieur de SQL Server, les threads, en mode utilisateur (user mode) (le système d’exploitation sous-jacent gère les threads en mode noyau (kernel mode)). La raison en est que SQL Server connaît mieux ses besoins de multitâche que le système d’exploitation.
Windows gère les threads de façon dite préemptive, c’est-à-dire qu’il force les processus à s’arrêter pour laisser du temps aux processus concurrents. Les ordonnanceurs de SQL Server fonctionnent en mode non-préemptif : à l’intérieur de SQLOS, les processus laissent eux-même la place aux autres, dans un mode collaboratif, ce qui permet d’obtenir de meilleures performances.
Un ordonnanceur est lié à un processeur physique. Il gère plusieurs threads, qui sont eux-mêmes liés à des workers. Le worker est le processus de travail. Il exécute un travail complètement, ce qui évite les changements de contextes qui peuvent se produire en cas de multitâche préemptif.
Un changement de contexte (context switch) représente la nécessité, pour un processus, de sauver son état lorsqu’il donne la main, puis de le recharger lorsqu’il reprend le travail, comme un travailleur doit déposer ses affaire dans son placard en partant, et les reprendre en revenant. Certains threads à l’intérieur de l’espace de SQL Server ne sont pas lancés par SQL Server, c’est le cas lors de l’exécution de procédures stockées étendues. Nous voyons tout cela schématiquement sur la figure 2.4, avec les vues de gestions dynamique qui correspondent.
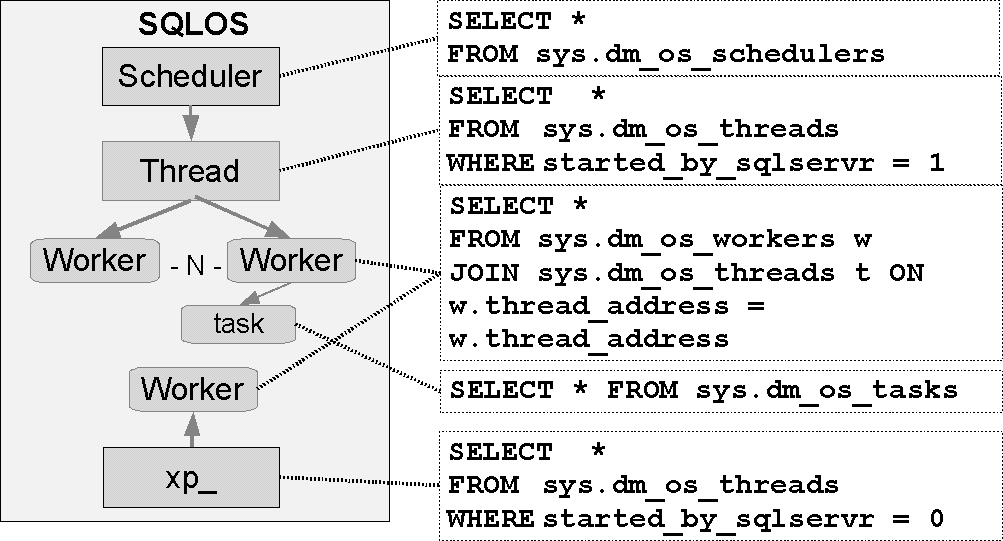
Ces vues vous permettent de voir les processus en activité, la mémoire de travail utilisée par chacun, s’ils sont en travail ou en attente, etc.
Outre la gestion locale des processus, SQLOS assure aussi la gestion locale de l’allocation mémoire. Un Memory Broker calcule dynamiquement les quantités optimales de RAM pour les différents objets en mémoires. Ces objets sont des caches (buffers), des pools, qui gèrent des objets plus simples que les caches, par exemple la mémoire pour les verrous, et des clerks, qui sont des gestionnaire d’espace mémoire fournissant des services d’allocation et de notification d’état de la mémoire. Ces différents éléments sont reproduits sur la figure 2.5.
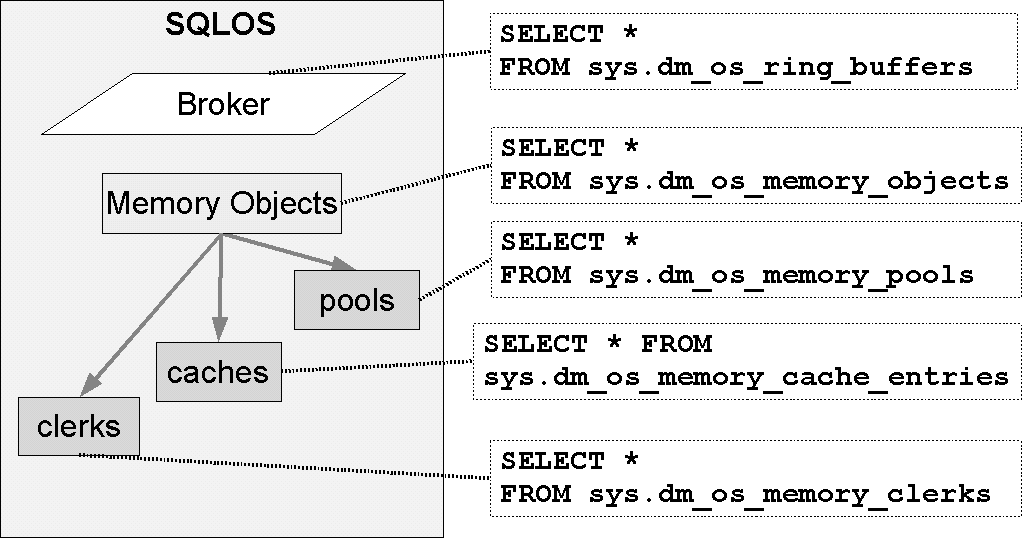
Des vues de gestion dynamique pour donnent des informations sur les caches :
sys.dm_exec_cached_plans;sys.dm_os_buffer_descriptors;sys.dm_os_memory_cache_clock_hands;sys.dm_os_memory_cache_counters;sys.dm_os_memory_cache_entries;sys.dm_os_memory_cache_hash_tables.
Nous reverrons certaines de ces vues dans notre chapitre sur le choix du matériel. Regardez ces vues, lorsque vous avec une compréhension générale de SQL Server, elles vous sont utiles pour détecter des problèmes éventuels, comme de la pression mémoire, ou des contentions de CPU.
Notes
Le protocole TDS est décrit sur le site de Sybase : TDS Version ↩︎
Le protocole MS-TDS est maintenant décrit dans le MSDN : [MS-TDS]: Tabular Data Stream Protocol](http://msdn.microsoft.com/en-us/library/dd304523.aspx) ↩︎
Session est le terme officiel pour une connexion utilisateur. ↩︎
disponibles par exemple sur le blog de Paul Randal : http://blogs.msdn.com/sqlserverstorageengine/ ↩︎
Voir nomenclature en début d’ouvrage. Le drapeau de trace permet de modifier des options internes de SQL Server. ↩︎